We at Crack4sure are committed to giving students who are preparing for the CompTIA DA0-001 Exam the most current and reliable questions . To help people study, we've made some of our CompTIA Data+ Certification Exam exam materials available for free to everyone. You can take the Free DA0-001 Practice Test as many times as you want. The answers to the practice questions are given, and each answer is explained.
Which of the following report types is most appropriate for a high-level, year-end report requested by a Chief Executive Officer?
Which of the following defines the policies and procedures for managing the master data?
A data analyst wants to create "Income Categories" that would be calculated based on the existing variable "Income". The "Income Categories" would be as follows:
Income category 1: less than $1.
Income category 2: more than $1 and less than $20,000.
Income category 3: more than $20,001 and less than $40,000.
Income category 4: more than $40,001.
Which of the following data manipulation techniques should the data analyst use to create "Income Categories"?
Which of the following is a domain-specific language used in programming that is designed for managing data that is held in a relational data stream management system?
An analyst reviews the following table:

Which of the following data types is represented in the values in the RefNo column?
An analyst wants to include a graph in a quarterly sales report that shows the comparison between two quantitative variables. Which of the following visual diagrams can the analyst use to most effectively represent this relationship?
A customer survey reveals 90% positive feedback. Which of the following statistical methods would be best to utilize to determine the reliability of a data set and predict how a larger sample of customers over the same time period might respond?
An analyst is designing a dashboard that will provide a story of the sales and sales customer ratio. The following data is available:
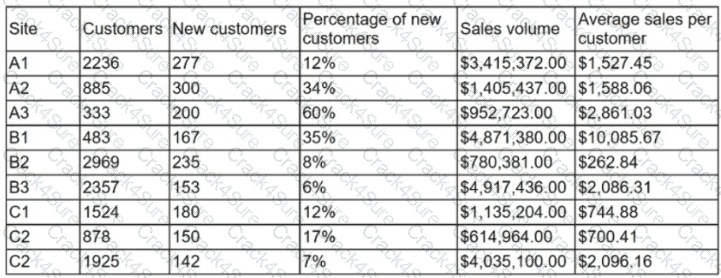
Which of the following charts should the analyst consider including in the dashboard?
Which of the following file formats is best suited to start exploratory analysis within statistical software?
An analyst has been asked to validate data quality. Which of the following are the BEST reasons to validate data for quality control purposes? (Choose two.)
Which of the following types of analyses is best to use when tracking sales revenue against quarterly targets?
Which of the ing is the correct ion for a tab-delimited spre file?
Five dogs have the following heights in millimeters:
300, 430, 170, 470, 600
Which of the following is the mean height for the five dogs?
A reporting analyst is creating a dashboard that shows the year-over-year performance for a sales organization. Which of the following is the best visual for the analyst use to illustrate the organization's performance?
Given the table below:
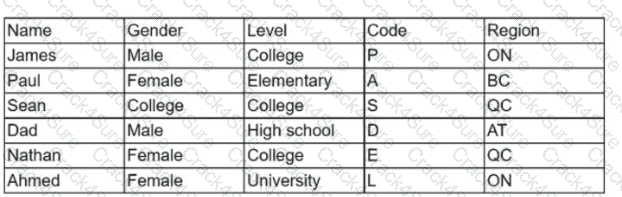
Which of the following variables can be considered inconsistent, and how many distinct values should the variable have?
Which of the following is a characteristic of a relational database?
A data analyst needs to create a weekly recurring report on sales performance and distribute it to all sales managers. Which of the following would be the BEST method to automate and ensure successful delivery for this task?
Amanda needs to create a dashboard that will draw information from many other data sources and present it to business leaders.
Which one of the following tools is least likely to meet her needs?
Under which of the following circumstances should the null hypothesis be accepted when a = 0.05?
A data analyst needs to present the results of an online marketing campaign to the marketing manager. The manager wants to see the most important KPIs and measure the return on marketing investment. Which of the following should the data analyst use to BEST communicate this information to the manager?
Which of the following types of analysis would be best for an analyst to use to examine the relationships between authors who cited other authors in a library of research papers?
Different people manually type a series of handwritten surveys into an online database. Which of the following issues will MOST likely arise with this data? (Choose two.)
A data analyst who works for a government agency is required to obtain the average income of citizens. The list of citizens is given in the following table:
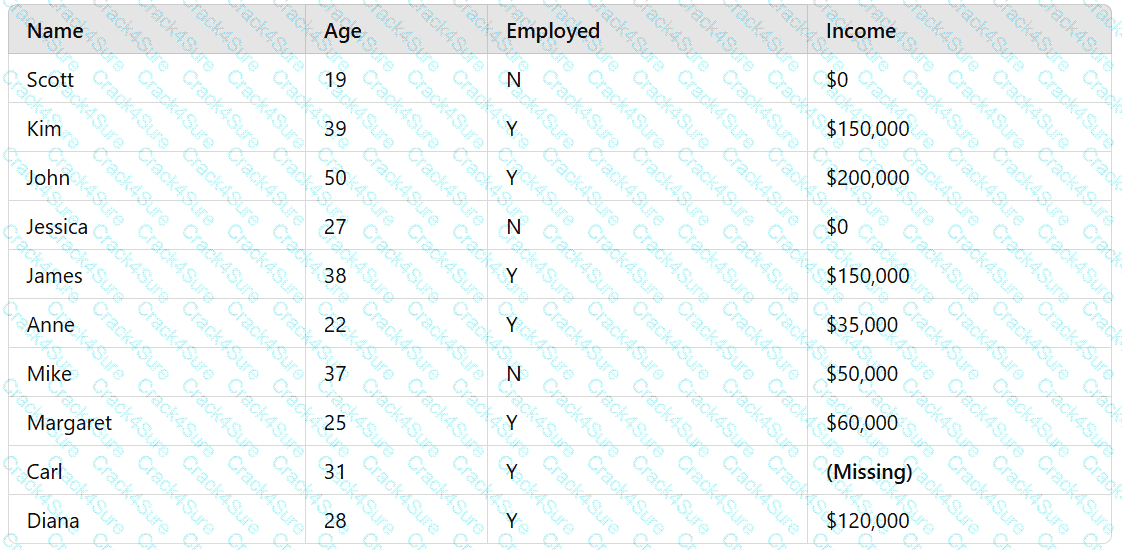
A value for one citizen's income is missing. Which of the following approaches should the data analyst take to solve this issue?
Given the below:

Which of the following numbers represents a Type I error?
Given the diagram below:
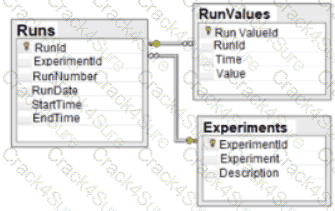
Which of the following data schemas shown?
An analyst modified a data set that had a number of issues. Given the original and modified versions:
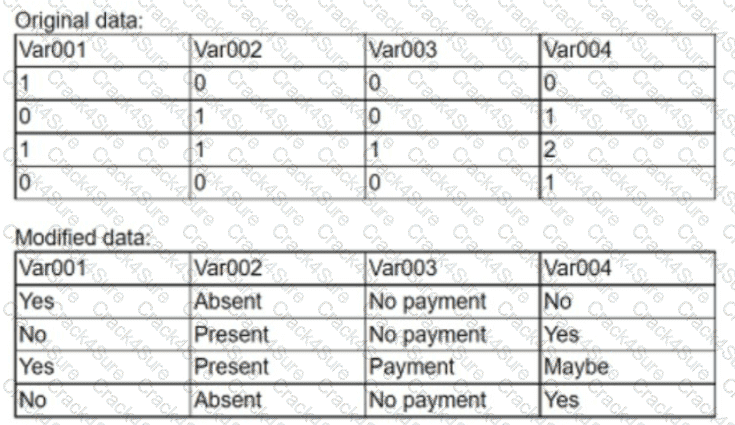
Which of the following data manipulation techniques did the analyst use?
Given the customer table below:

Which of the following chart types is the most appropriate to represent the average spending of active customers vs. inactive customers?
A military commander would like to see the health scorecards of the troops daily and filter them based on gender and rank. Considering this data is PHI, which of the following would be the best way for the commander to view the information?
Which of the following is the most appropriate to consider when creating a schema of a central group broken into detailed subcategories?
An analyst notices changes in sales ratios when analyzing a quarterly report. Which of the following is the analyst conducting?
Which of the following tools would be best to use to calculate the interquartile range, median, mean, and standard deviation of a column in a table that has 5.000.000 rows?
You are working with a dataset and want to change the names of categories that you used fordifferent types of books.
What term best describes this action?
Which one of the following values will appear first if they are sorted in descending order?
A healthcare data analyst notices that one data set in the column for BloodPressure contains several outliers that need to be replaced with meaningful values. Which of the following data manipulation techniques should the analyst use?
A marketing analytics team received customer transaction data from two different sources. The data is complete and accurate; however, the field names appear to be inconsistent. Given the following tables:
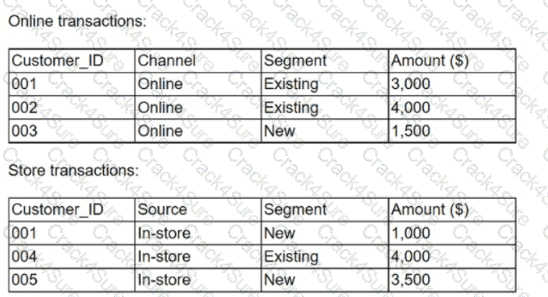
Which of the following is considered best practice if the team wants to consolidate the files and conduct further analysis?
An analyst wants to determine whether a relationship between an individual's age and voting preferences exists. Which of the following is the best statistical method for the analyst to use?
An organizational document governs role-based and group-based requirements. Which of the following data requirements should be used?
A company notifies its employees that emails will be automatically moved to a cloud-based server in 180 days. Which of the following describes this concept?
A data analyst has been asked to derive a new variable labeled “Promotion_flag” based on the total quantity sold by each salesperson. Given the table below:
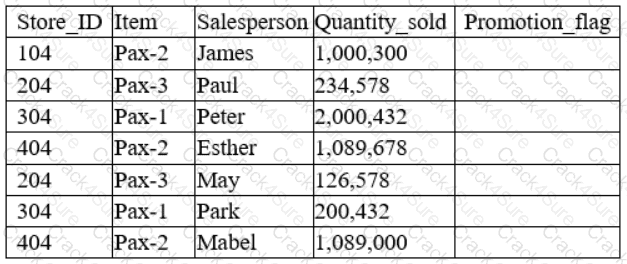
Which of the following functions would the analyst consider appropriate to flag “Yes” for every salesperson who has a number above 1,000,000 in the Quantity_sold column?
An analyst is currently working on a ticket for revamping a company-wide dashboard that has been in use for five years. Which of the following should be the first step in the development process?
Which one of the following is a common data warehouse schema?
An e-commerce company recently tested a new website layout. The website was tested by a test group of customers, and an old website was presented to a control group. The table below shows the percentage of users in each group who made purchases on the websites:
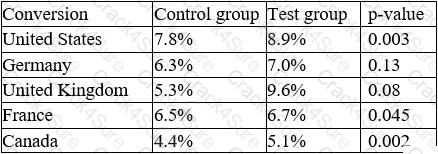
Which of the following conclusions is accurate at a 95% confidence interval?
You have two databases tables that you would like to join together using a foreign key relationship.
What term best describes this action?
Which of the following is an example of a discrete data type?
Which of the following describes the use of a representative amount of data from a main repository?
Given the following data:
CustomerID
ItemBought
Date
Tre_234
Sofa
2022-09-08
216_Tre
Shoes
08/02/2021
215/Tre
Blanket
2021/06/20
045/Tre
Mug
12-26-2021
Tre-345
Lamp
31/08/2022
TREJD19
Bucket
2022'08/01
Which of the following best describes the main issue in the data set?
An analyst is currently working on a ticket to revamp a company-wide dashboard that has been in use for five years. Which of the following should be the first step in the development process?
Which of the following best describes a 95% confidence interval?
Which of the following is used for calculations and pivot tables?
Given the following data sample:
Which of the following best describes the data quality issue?
Which of the following is the best approach to use to gain a general understanding of a data set?
A client wants a new report that will be automatically emailed to all global sales teams on a weekly basis. Each sales team must be able to view the sales for its region and the combined sales for all regions. Which of the following would be the most efficient method for meeting the requirements?
Given the following data set:

Which of the following is the best reason for cleansing the data?
Given the following table:

Which of the following describes the data quality issues with theagedata?
Which of the following is the best reason for removing data outliers?
A data analyst has been asked to create a sales report that calculates the rolling 12-month average for sales. If the report will be published on November 1, 2020, which of the following months shouts the report cover?
A web developer wants to ensure that malicious users can't type SQL statements when they asked for input, like their username/userid.
Which of the following query optimization techniques would effectively prevent SQL Injection attacks?
A data analyst is creating a report that will provide information about various regions, products, and time periods. Which of the following formats would be themost efficient way to deliver this report?
A JSON file is an example of:
A data analyst was asked to create a visual representation of sales for the first quarter of 2020. Which of the following visualizations should be used when a time element is present?
An analyst is working with the income data of suburban families in the United States. The data set has a lot of outliers, and the analyst needs to provide a measure that represents the typical income. Which of the following would BEST fulfill the analyst’s goal?
An analyst for a concert venue is analyzing the number of tickets sold for a recent event. Which of the following types of data is the number of sold tickets an example of?
An analyst is reporting on the average income for a county and is reviewing the following data:

Which of the following is the reason the analyst would need to cleanse the data in this data set?
A data analyst is reviewing SQL code and sees a query that uses terms such as MIN, SUM, and COUNT. Which of the following types of functions best describes these terms?
Each month an analyst needs to execute a data pull for the two prior months. Which of the following is the most efficient function for the analyst to use?
A customer list from a financial services company is shown below:
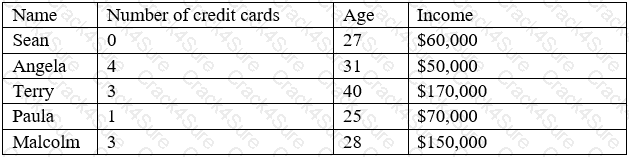
A data analyst wants to create a likely-to-buy score on a scale from 0 to 100, based on an average of the three numerical variables: number of credit cards, age, and income. Which of the following should the analyst do to the variables to ensure they all have the same weight in the score calculation?
Which of the following is an example of a flat file?
Given the information in the following tables:
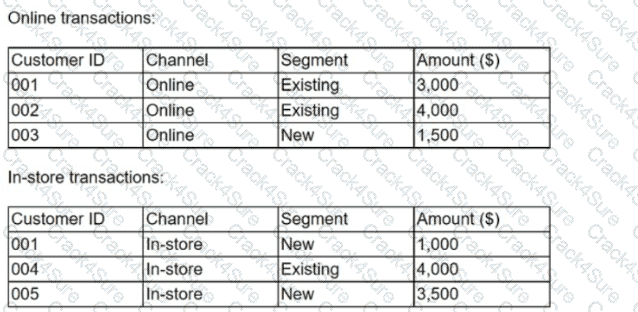
Which of the following describes merging these tables to create a master file that includes all transactions for both online and in-store sales?
A data analyst needs to observe the relationship between two numeric variables and identify the clustering pattern as well as the outliers. Which of the following visualizations should the analyst use?
Which of the following query optimization techniques involves examining only the data that is needed for a particular task?
Which of the following will MOST likely be streamed live?
Which of the following is the correct data type for text?
Which of the following is a common data analytics tool that is also used as an interpreted, high-level, general-purpose programming language?
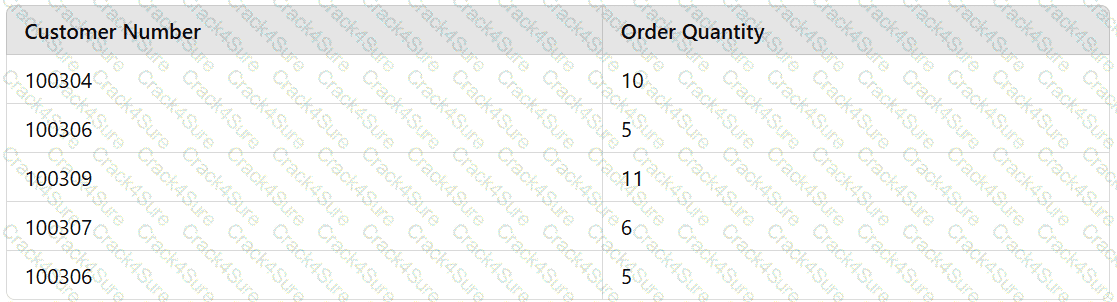
A data analyst is designing a dashboard that will provide a story of sales and determine which site is providing the highest sales volume per customer The analyst must choose an appropriate chart to include in the dashboard. The following data is available:
Which of the following types of charts should be considered?
Which of the following are reasons to conduct data cleansing? (Select two).
Which of the following is a common data analytics tool that is also used as an interpreted, high-level, general-purpose programming language?
Which of the following best describes the law of large numbers?
A data analyst is working with a team to create a dashboard for a client who requires on-demand access. Which of the following is the best delivery method to support the clients’ requirement?
A database consists of one fact table that is composed of multiple dimensions. Each dimension is represented by a denormalized table. This structure is an example of a:
An analyst wants to include a graph in a quarterly sales report that shows the comparison between two quantitative variables. Which of the following visual diagrams can the analyst use to most effectively represent this relationship?
Which of the following types of data manipulation functions should a data analyst use to implement a YES/NO condition in a spreadsheet?
A dataset requires an analysis for investigating and discovering abnormalities. Which of the following best describes the nature of the exploratory analysis conducted?
A data analyst is developing a data dictionary that aligns with a company's data management processes and policies. Which of the following best describes what should be included in the data dictionary?
A company wants to know how its customers interact with an e-commerce website based on clicks over items. Which of the following is the primary requirement for this report?
A data scientist wants to see which products make the most money and which products attract the most customer purchasing interest in their company.
Which of the following data manipulation techniques would he use to obtain this information?
Which of the following techniques is used to quantify data?
A database consists of one fact table that is composed of multiple dimensions. Each dimension is represented by a denormalized table. This structure is an example of a:
Five dogs have the following heights in millimeters:
300,430, 170, 470, 600
Which of the following is the standard deviation for the five dogs?
A data analyst is attempting to understand how ice cream consumption is affected by different attributes. such as cost, temperature. and income level. Which of the following
regression analyses should the data analyst perform to understand this relationship?
A data set has the following values:

Which of the following is the best reason for cleansing the data?
Which of the following query statements would be used when filtering data in a relational database management system? (Select two).
An analyst wants to create a historical data set for the past five years with each year in its own data set. Which of the following methods is the best way to create this historical data set?
A data analyst has removed the outliers from a data set due to large variances. Which of the following central tendencies would be the best measure to use?
A data analyst is asked to create a sales report for the second-quarter 2020 board meeting, which will include a review of the business’s performance through the second quarter. The board meeting will be held on July 15, 2020, after the numbers are finalized. Which of the following report types should the data analyst create?
A database administrator needs to increase performance on a large dimension table. Which of the following is the best way to accomplish this task?
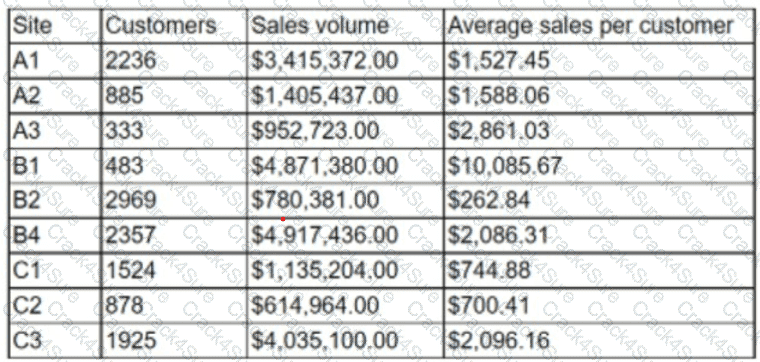
An analyst is designing a dashboard to determine which site has the highest percentage of new customers. The analyst must choose an appropriate chart to include in the dashboard. The following data is available:
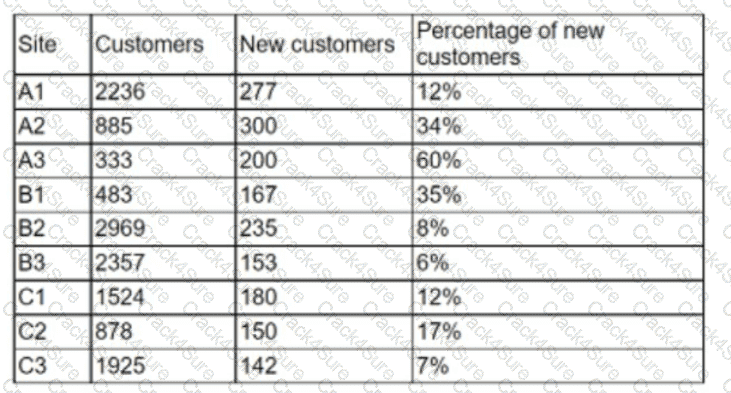
Which of the following types of charts should be considered to best display the data?
A data analyst must fulfill a request for information that is needed weekly and should be automatically emailed to a specific set of users. Which of the following types of reports should theanalyst recommend?
An analyst needs to create an analytics dashboard for an employee intranet site to improve the search functionality, display relevant information, and maintain an updated FAQ page. Which of the following visualizations would best represent what employees are searching for?
The current date is July 14, 2020. A data analyst has been asked to create a report that shows the company's year-over-year Q2 2020 sales. Which of the following reports should the analyst compare?
A collections manager has a team calling customers who are past due on their accounts in an attempt to collect payments. The manager receives the call list in the form of a printed report that is generated by the accounting department at the beginning of each week. Consequently, the collections team calls some customers who have made payments in the time since the report was last printed. Which of the following reporting enhancements could the accounting department implement to best reduce the number of calls on current accounts?
A data analyst is building a closed won quarter-over-quarter report for the sales team. Which of the following will be needed to complete this request?
An analyst needs to join two tables of data together for analysis. All the names and cities in the first table should be joined with the corresponding ages in the second table, if applicable.
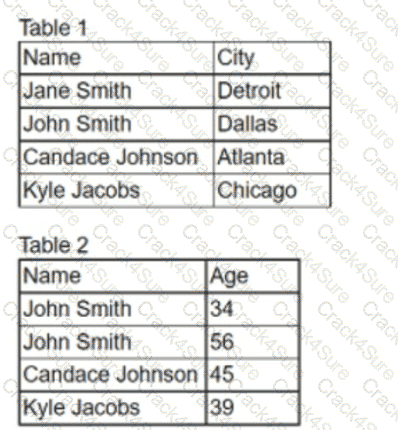
Which of the following is the correct join the analyst should complete. and how many total rows will be in one table?
A database administrator is required to mask certain table columns containing PII in order to comply with the company privacy policy. Which of the following are the most likely types of information the administrator should mask? (Select two).
A column is being used to store strings of variable lengths. Performance is a concern, so the column needs to use as little space as possible. Which of the following data types best meets these requirements?
An analyst has been tracking company intranet usage and has been asked to create a chat to show the most-used/most-clicked portions of a homepage that contains more than 30 links. Which of the following visualizations would BEST illustrate this information?
A data analyst for a media company needs to determine the most popular movie genre. Given the table below:
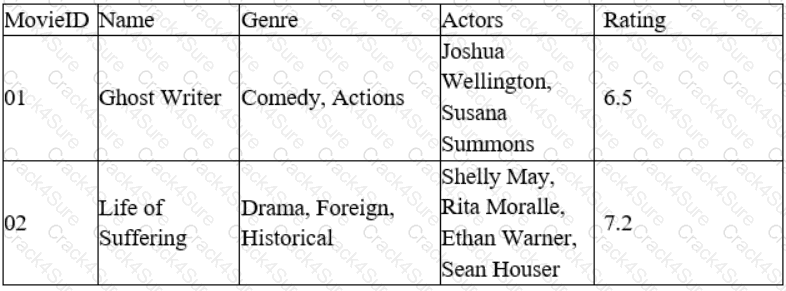
Which of the following must be done to the Genre column before this task can be completed?
Which of the following differentiates a flat text file from other data types?
Which of the following describes the method of sampling in which elements of data are selected randomly from each of the small subgroups within a population?
Which of the following roles is responsible for ensuring an organization's data quality, security, privacy, and regulatory compliance?
Consider the following dataset which contains information about houses that are for sale:

Which of the following string manipulation commands will combine the address and region namecolumns to create a full address?
full_address------------------------- 85 Turner St, Northern Metropolitan 25 Bloomburg St, Northern Metropolitan 5 Charles St, Northern Metropolitan 40 Federation La, Northern Metropolitan 55a Park St, Northern Metropolitan
Which of the following explains why standardization of data field names is important to master data management concepts?
An analyst wants to extract data from a variety of sources and store the data in a cloud-based environment prior to cleaning. Which of the following integration techniques should the analyst use?
Which of the following programming languages are best suited for analysis and machine-learning applications? (Select two).
3 Months Free Update
3 Months Free Update
3 Months Free Update

TESTED 29 Jul 2026