We at Crack4sure are committed to giving students who are preparing for the Confluent CCDAK Exam the most current and reliable questions . To help people study, we've made some of our Confluent Certified Developer for Apache Kafka Certification Examination exam materials available for free to everyone. You can take the Free CCDAK Practice Test as many times as you want. The answers to the practice questions are given, and each answer is explained.
You need to consume messages from Kafka using the command-line interface (CLI).
Which command should you use?
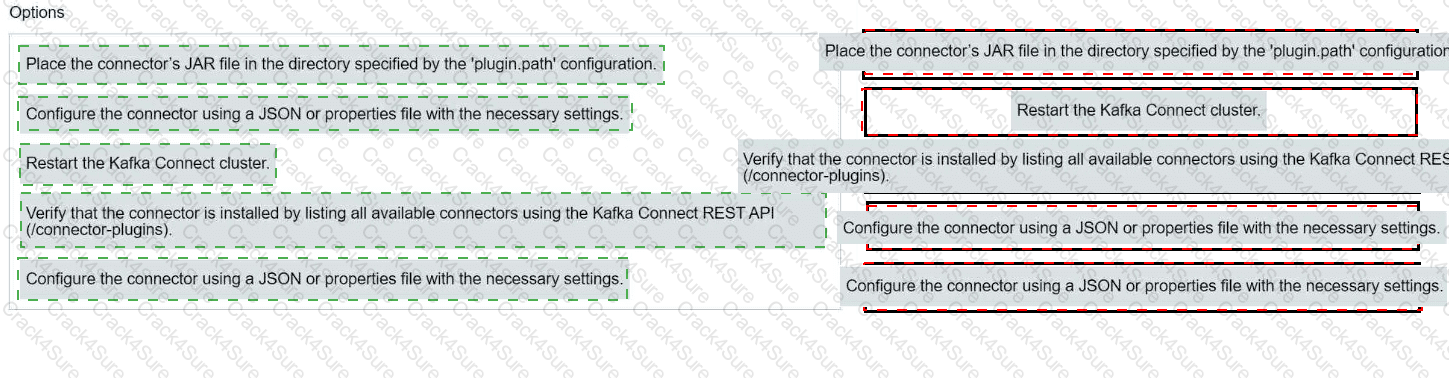
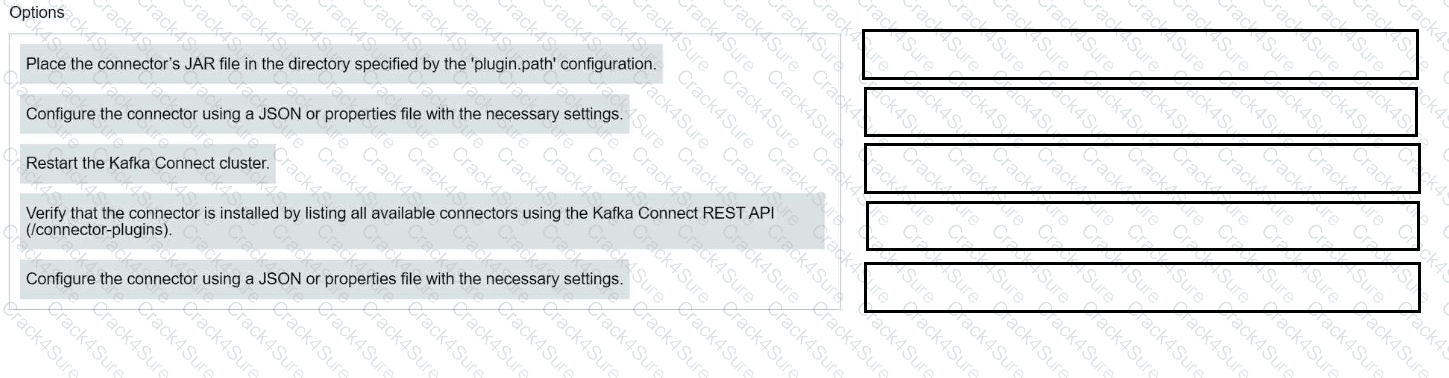
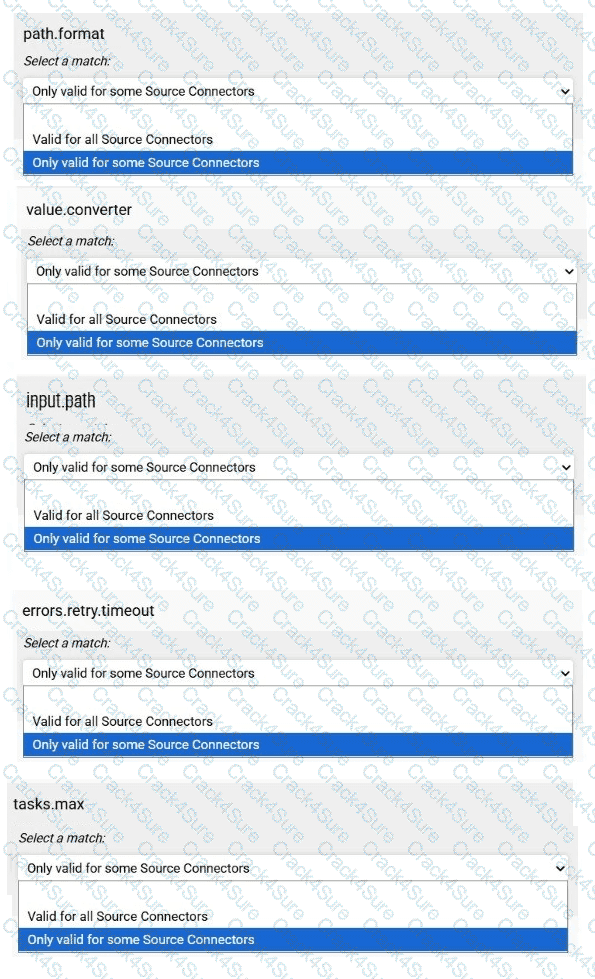
Match each configuration parameter with the correct deployment step in installing a Kafka connector.
(An S3 source connector named s3-connector stopped running.
You use the Kafka Connect REST API to query the connector and task status.
One of the three tasks has failed.
You need to restart the connector and all currently running tasks.
Which REST request will restart the connector instance and all its tasks?)
Which configuration allows more time for the consumer poll to process records?
(You are building real-time streaming applications using Kafka Streams.
Your application has a custom transformation.
You need to define custom processors in Kafka Streams.
Which tool should you use?)
(Which configuration is valid for deploying a JDBC Source Connector to read all rows from the orders table and write them to the dbl-orders topic?)
You are developing a Java application using a Kafka consumer.
You need to integrate Kafka’s client logs with your own application’s logs using log4j2.
Which Java library dependency must you include in your project?
You use Kafka Connect with the JDBC source connector to extract data from a large database and push it into Kafka.
The database contains tens of tables, and the current connector is unable to process the data fast enough.
You add more Kafka Connect workers, but throughput doesn't improve.
What should you do next?
(You create an Orders topic with 10 partitions.
The topic receives data at high velocity.
Your Kafka Streams application initially runs on a server with four CPU threads.
You move the application to another server with 10 CPU threads to improve performance.
What does this example describe?)
(Which configuration determines the maximum number of records a consumer can poll in a single call to poll()?)
Your company has three Kafka clusters: Development, Testing, and Production.
The Production cluster is running out of storage, so you add a new node.
Which two statements about the new node are true?
(Select two.)
A stream processing application is tracking user activity in online shopping carts.
You want to identify periods of user inactivity.
Which type of Kafka Streams window should you use?
You need to set alerts on key broker metrics to trigger notifications when the cluster is unhealthy.
Which are three minimum broker metrics to monitor?
(Select three.)
You have a topic t1 with six partitions. You use Kafka Connect to send data from topic t1 in your Kafka cluster to Amazon S3. Kafka Connect is configured for two tasks.
How many partitions will each task process?
You need to correctly join data from two Kafka topics.
Which two scenarios will allow for co-partitioning?
(Select two.)
You are writing to a topic with acks=all.
The producer receives acknowledgments but you notice duplicate messages.
You find that timeouts due to network delay are causing resends.
Which configuration should you use to prevent duplicates?
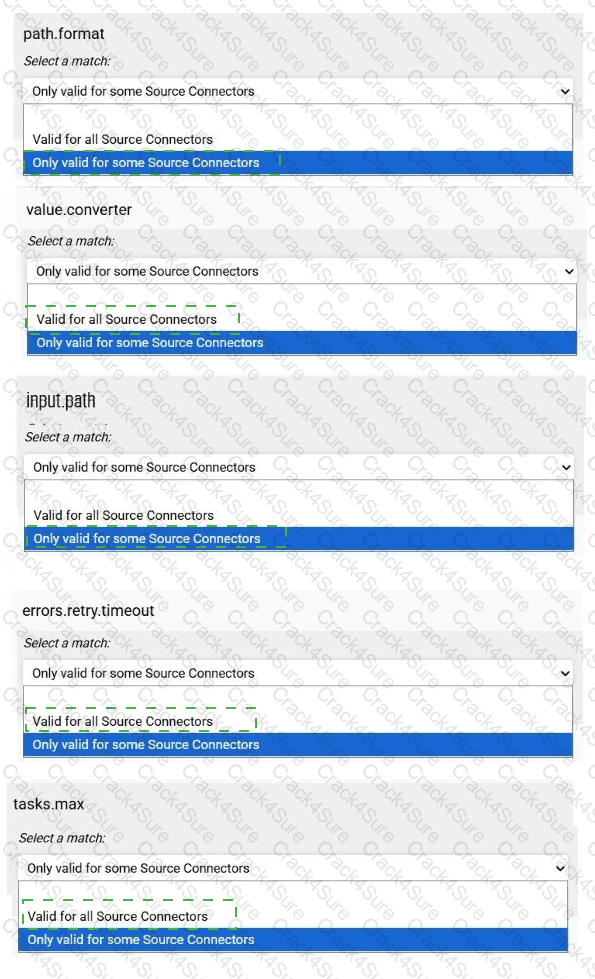
Match each configuration parameter with the correct option.
To answer choose a match for each option from the drop-down. Partial
credit is given for each correct answer.
(You want to read messages from all partitions of a topic in every consumer instance of your application.
How do you do this?)
What are three built-in abstractions in the Kafka Streams DSL?
(Select three.)
You are creating a Kafka Streams application to process retail data.
Match the input data streams with the appropriate Kafka Streams object.
You have a topic with four partitions. The application reads from it using two consumers in a single consumer group.
Processing is CPU-bound, and lag is increasing.
What should you do?
What is the default maximum size of a message the Apache Kafka broker can accept?
3 Months Free Update
3 Months Free Update
3 Months Free Update

TESTED 10 Jul 2026