We at Crack4sure are committed to giving students who are preparing for the Databricks Databricks-Certified-Associate-Developer-for-Apache-Spark-3.0 Exam the most current and reliable questions . To help people study, we've made some of our Databricks Certified Associate Developer for Apache Spark 3.0 Exam exam materials available for free to everyone. You can take the Free Databricks-Certified-Associate-Developer-for-Apache-Spark-3.0 Practice Test as many times as you want. The answers to the practice questions are given, and each answer is explained.
Which of the following code blocks returns a DataFrame showing the mean value of column "value" of DataFrame transactionsDf, grouped by its column storeId?
Which of the following code blocks selects all rows from DataFrame transactionsDf in which column productId is zero or smaller or equal to 3?
The code block shown below should store DataFrame transactionsDf on two different executors, utilizing the executors' memory as much as possible, but not writing anything to disk. Choose the
answer that correctly fills the blanks in the code block to accomplish this.
1.from pyspark import StorageLevel
2.transactionsDf.__1__(StorageLevel.__2__).__3__
Which of the following statements about garbage collection in Spark is incorrect?
Which of the following describes characteristics of the Spark UI?
The code block displayed below contains an error. The code block should return DataFrame transactionsDf, but with the column storeId renamed to storeNumber. Find the error.
Code block:
transactionsDf.withColumn("storeNumber", "storeId")
Which of the following code blocks efficiently converts DataFrame transactionsDf from 12 into 24 partitions?
The code block shown below should convert up to 5 rows in DataFrame transactionsDf that have the value 25 in column storeId into a Python list. Choose the answer that correctly fills the blanks in
the code block to accomplish this.
Code block:
transactionsDf.__1__(__2__).__3__(__4__)
Which of the following code blocks returns all unique values across all values in columns value and productId in DataFrame transactionsDf in a one-column DataFrame?
Which of the following code blocks returns a new DataFrame with the same columns as DataFrame transactionsDf, except for columns predError and value which should be removed?
The code block displayed below contains an error. The code block should return a new DataFrame that only contains rows from DataFrame transactionsDf in which the value in column predError is
at least 5. Find the error.
Code block:
transactionsDf.where("col(predError) >= 5")
The code block shown below should return a two-column DataFrame with columns transactionId and supplier, with combined information from DataFrames itemsDf and transactionsDf. The code
block should merge rows in which column productId of DataFrame transactionsDf matches the value of column itemId in DataFrame itemsDf, but only where column storeId of DataFrame
transactionsDf does not match column itemId of DataFrame itemsDf. Choose the answer that correctly fills the blanks in the code block to accomplish this.
Code block:
transactionsDf.__1__(itemsDf, __2__).__3__(__4__)
The code block shown below should write DataFrame transactionsDf to disk at path csvPath as a single CSV file, using tabs (\t characters) as separators between columns, expressing missing
values as string n/a, and omitting a header row with column names. Choose the answer that correctly fills the blanks in the code block to accomplish this.
transactionsDf.__1__.write.__2__(__3__, " ").__4__.__5__(csvPath)
The code block displayed below contains an error. The code block should merge the rows of DataFrames transactionsDfMonday and transactionsDfTuesday into a new DataFrame, matching
column names and inserting null values where column names do not appear in both DataFrames. Find the error.
Sample of DataFrame transactionsDfMonday:
1.+-------------+---------+-----+-------+---------+----+
2.|transactionId|predError|value|storeId|productId| f|
3.+-------------+---------+-----+-------+---------+----+
4.| 5| null| null| null| 2|null|
5.| 6| 3| 2| 25| 2|null|
6.+-------------+---------+-----+-------+---------+----+
Sample of DataFrame transactionsDfTuesday:
1.+-------+-------------+---------+-----+
2.|storeId|transactionId|productId|value|
3.+-------+-------------+---------+-----+
4.| 25| 1| 1| 4|
5.| 2| 2| 2| 7|
6.| 3| 4| 2| null|
7.| null| 5| 2| null|
8.+-------+-------------+---------+-----+
Code block:
sc.union([transactionsDfMonday, transactionsDfTuesday])
The code block displayed below contains an error. The code block should return the average of rows in column value grouped by unique storeId. Find the error.
Code block:
transactionsDf.agg("storeId").avg("value")
Which of the following code blocks generally causes a great amount of network traffic?
The code block shown below should return a single-column DataFrame with a column named consonant_ct that, for each row, shows the number of consonants in column itemName of DataFrame
itemsDf. Choose the answer that correctly fills the blanks in the code block to accomplish this.
DataFrame itemsDf:
1.+------+----------------------------------+-----------------------------+-------------------+
2.|itemId|itemName |attributes |supplier |
3.+------+----------------------------------+-----------------------------+-------------------+
4.|1 |Thick Coat for Walking in the Snow|[blue, winter, cozy] |Sports Company Inc.|
5.|2 |Elegant Outdoors Summer Dress |[red, summer, fresh, cooling]|YetiX |
6.|3 |Outdoors Backpack |[green, summer, travel] |Sports Company Inc.|
7.+------+----------------------------------+-----------------------------+-------------------+
Code block:
itemsDf.select(__1__(__2__(__3__(__4__), "a|e|i|o|u|\s", "")).__5__("consonant_ct"))
The code block displayed below contains an error. The code block below is intended to add a column itemNameElements to DataFrame itemsDf that includes an array of all words in column
itemName. Find the error.
Sample of DataFrame itemsDf:
1.+------+----------------------------------+-------------------+
2.|itemId|itemName |supplier |
3.+------+----------------------------------+-------------------+
4.|1 |Thick Coat for Walking in the Snow|Sports Company Inc.|
5.|2 |Elegant Outdoors Summer Dress |YetiX |
6.|3 |Outdoors Backpack |Sports Company Inc.|
7.+------+----------------------------------+-------------------+
Code block:
itemsDf.withColumnRenamed("itemNameElements", split("itemName"))
itemsDf.withColumnRenamed("itemNameElements", split("itemName"))
Which of the following code blocks prints out in how many rows the expression Inc. appears in the string-type column supplier of DataFrame itemsDf?
The code block shown below should return a column that indicates through boolean variables whether rows in DataFrame transactionsDf have values greater or equal to 20 and smaller or equal to
30 in column storeId and have the value 2 in column productId. Choose the answer that correctly fills the blanks in the code block to accomplish this.
transactionsDf.__1__((__2__.__3__) __4__ (__5__))
The code block shown below should add column transactionDateForm to DataFrame transactionsDf. The column should express the unix-format timestamps in column transactionDate as string
type like Apr 26 (Sunday). Choose the answer that correctly fills the blanks in the code block to accomplish this.
transactionsDf.__1__(__2__, from_unixtime(__3__, __4__))
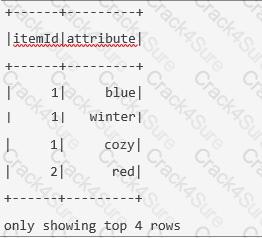
The code block displayed below contains an error. The code block should create DataFrame itemsAttributesDf which has columns itemId and attribute and lists every attribute from the attributes column in DataFrame itemsDf next to the itemId of the respective row in itemsDf. Find the error.
A sample of DataFrame itemsDf is below.

Code block:
itemsAttributesDf = itemsDf.explode("attributes").alias("attribute").select("attribute", "itemId")
Which of the following code blocks returns a single-column DataFrame of all entries in Python list throughputRates which contains only float-type values ?
Which of the following code blocks reorders the values inside the arrays in column attributes of DataFrame itemsDf from last to first one in the alphabet?
1.+------+-----------------------------+-------------------+
2.|itemId|attributes |supplier |
3.+------+-----------------------------+-------------------+
4.|1 |[blue, winter, cozy] |Sports Company Inc.|
5.|2 |[red, summer, fresh, cooling]|YetiX |
6.|3 |[green, summer, travel] |Sports Company Inc.|
7.+------+-----------------------------+-------------------+
The code block shown below should return a new 2-column DataFrame that shows one attribute from column attributes per row next to the associated itemName, for all suppliers in column supplier
whose name includes Sports. Choose the answer that correctly fills the blanks in the code block to accomplish this.
Sample of DataFrame itemsDf:
1.+------+----------------------------------+-----------------------------+-------------------+
2.|itemId|itemName |attributes |supplier |
3.+------+----------------------------------+-----------------------------+-------------------+
4.|1 |Thick Coat for Walking in the Snow|[blue, winter, cozy] |Sports Company Inc.|
5.|2 |Elegant Outdoors Summer Dress |[red, summer, fresh, cooling]|YetiX |
6.|3 |Outdoors Backpack |[green, summer, travel] |Sports Company Inc.|
7.+------+----------------------------------+-----------------------------+-------------------+
Code block:
itemsDf.__1__(__2__).select(__3__, __4__)
Which of the following code blocks returns a copy of DataFrame transactionsDf that only includes columns transactionId, storeId, productId and f?
Sample of DataFrame transactionsDf:
1.+-------------+---------+-----+-------+---------+----+
2.|transactionId|predError|value|storeId|productId| f|
3.+-------------+---------+-----+-------+---------+----+
4.| 1| 3| 4| 25| 1|null|
5.| 2| 6| 7| 2| 2|null|
6.| 3| 3| null| 25| 3|null|
7.+-------------+---------+-----+-------+---------+----+
The code block shown below should show information about the data type that column storeId of DataFrame transactionsDf contains. Choose the answer that correctly fills the blanks in the code
block to accomplish this.
Code block:
transactionsDf.__1__(__2__).__3__
Which of the following describes Spark actions?
Which of the following statements about reducing out-of-memory errors is incorrect?
The code block displayed below contains an error. The code block should count the number of rows that have a predError of either 3 or 6. Find the error.
Code block:
transactionsDf.filter(col('predError').in([3, 6])).count()
Which of the following code blocks reduces a DataFrame from 12 to 6 partitions and performs a full shuffle?
Which of the following describes a narrow transformation?
Which of the following describes a difference between Spark's cluster and client execution modes?
In which order should the code blocks shown below be run in order to return the number of records that are not empty in column value in the DataFrame resulting from an inner join of DataFrame
transactionsDf and itemsDf on columns productId and itemId, respectively?
1. .filter(~isnull(col('value')))
2. .count()
3. transactionsDf.join(itemsDf, col("transactionsDf.productId")==col("itemsDf.itemId"))
4. transactionsDf.join(itemsDf, transactionsDf.productId==itemsDf.itemId, how='inner')
5. .filter(col('value').isnotnull())
6. .sum(col('value'))
Which of the following code blocks returns a one-column DataFrame of all values in column supplier of DataFrame itemsDf that do not contain the letter X? In the DataFrame, every value should
only be listed once.
Sample of DataFrame itemsDf:
1.+------+--------------------+--------------------+-------------------+
2.|itemId| itemName| attributes| supplier|
3.+------+--------------------+--------------------+-------------------+
4.| 1|Thick Coat for Wa...|[blue, winter, cozy]|Sports Company Inc.|
5.| 2|Elegant Outdoors ...|[red, summer, fre...| YetiX|
6.| 3| Outdoors Backpack|[green, summer, t...|Sports Company Inc.|
7.+------+--------------------+--------------------+-------------------+
The code block displayed below contains an error. The code block should return a DataFrame in which column predErrorAdded contains the results of Python function add_2_if_geq_3 as applied to
numeric and nullable column predError in DataFrame transactionsDf. Find the error.
Code block:
1.def add_2_if_geq_3(x):
2. if x is None:
3. return x
4. elif x >= 3:
5. return x+2
6. return x
7.
8.add_2_if_geq_3_udf = udf(add_2_if_geq_3)
9.
10.transactionsDf.withColumnRenamed("predErrorAdded", add_2_if_geq_3_udf(col("predError")))
Which of the following code blocks returns only rows from DataFrame transactionsDf in which values in column productId are unique?
Which of the following describes Spark's standalone deployment mode?
The code block displayed below contains an error. The code block should save DataFrame transactionsDf at path path as a parquet file, appending to any existing parquet file. Find the error.
Code block:
Which of the following code blocks returns a new DataFrame in which column attributes of DataFrame itemsDf is renamed to feature0 and column supplier to feature1?
Which of the following statements about broadcast variables is correct?
The code block displayed below contains an error. When the code block below has executed, it should have divided DataFrame transactionsDf into 14 parts, based on columns storeId and
transactionDate (in this order). Find the error.
Code block:
transactionsDf.coalesce(14, ("storeId", "transactionDate"))
Which of the following code blocks stores DataFrame itemsDf in executor memory and, if insufficient memory is available, serializes it and saves it to disk?
Which of the following is a problem with using accumulators?
Which of the following code blocks creates a new DataFrame with 3 columns, productId, highest, and lowest, that shows the biggest and smallest values of column value per value in column
productId from DataFrame transactionsDf?
Sample of DataFrame transactionsDf:
1.+-------------+---------+-----+-------+---------+----+
2.|transactionId|predError|value|storeId|productId| f|
3.+-------------+---------+-----+-------+---------+----+
4.| 1| 3| 4| 25| 1|null|
5.| 2| 6| 7| 2| 2|null|
6.| 3| 3| null| 25| 3|null|
7.| 4| null| null| 3| 2|null|
8.| 5| null| null| null| 2|null|
9.| 6| 3| 2| 25| 2|null|
10.+-------------+---------+-----+-------+---------+----+
The code block shown below should return all rows of DataFrame itemsDf that have at least 3 items in column itemNameElements. Choose the answer that correctly fills the blanks in the code block
to accomplish this.
Example of DataFrame itemsDf:
1.+------+----------------------------------+-------------------+------------------------------------------+
2.|itemId|itemName |supplier |itemNameElements |
3.+------+----------------------------------+-------------------+------------------------------------------+
4.|1 |Thick Coat for Walking in the Snow|Sports Company Inc.|[Thick, Coat, for, Walking, in, the, Snow]|
5.|2 |Elegant Outdoors Summer Dress |YetiX |[Elegant, Outdoors, Summer, Dress] |
6.|3 |Outdoors Backpack |Sports Company Inc.|[Outdoors, Backpack] |
7.+------+----------------------------------+-------------------+------------------------------------------+
Code block:
itemsDf.__1__(__2__(__3__)__4__)
Which of the following describes a valid concern about partitioning?
Which of the following describes Spark's Adaptive Query Execution?
Which of the following statements about executors is correct, assuming that one can consider each of the JVMs working as executors as a pool of task execution slots?
3 Months Free Update
3 Months Free Update
3 Months Free Update

TESTED 05 Mar 2026

 C:\Users\Admin\Desktop\Data\Odt data\Untitled.jpg
C:\Users\Admin\Desktop\Data\Odt data\Untitled.jpg