We at Crack4sure are committed to giving students who are preparing for the Databricks Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Exam the most current and reliable questions . To help people study, we've made some of our Databricks Certified Associate Developer for Apache Spark 3.5 – Python exam materials available for free to everyone. You can take the Free Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Practice Test as many times as you want. The answers to the practice questions are given, and each answer is explained.
A data engineer replaces the exact percentile() function with approx_percentile() to improve performance, but the results are drifting too far from expected values.
Which change should be made to solve the issue?
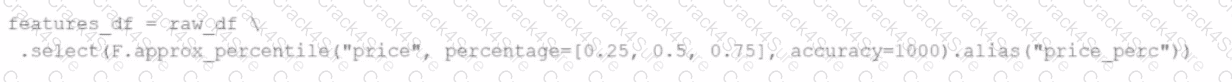
A data engineer is building a Structured Streaming pipeline and wants the pipeline to recover from failures or intentional shutdowns by continuing where the pipeline left off.
How can this be achieved?
46 of 55.
A data engineer is implementing a streaming pipeline with watermarking to handle late-arriving records.
The engineer has written the following code:
inputStream \
.withWatermark("event_time", "10 minutes") \
.groupBy(window("event_time", "15 minutes"))
What happens to data that arrives after the watermark threshold?
44 of 55.
A data engineer is working on a real-time analytics pipeline using Spark Structured Streaming.
They want the system to process incoming data in micro-batches at a fixed interval of 5 seconds.
Which code snippet fulfills this requirement?
A data scientist at a financial services company is working with a Spark DataFrame containing transaction records. The DataFrame has millions of rows and includes columns for transaction_id, account_number, transaction_amount, and timestamp. Due to an issue with the source system, some transactions were accidentally recorded multiple times with identical information across all fields. The data scientist needs to remove rows with duplicates across all fields to ensure accurate financial reporting.
Which approach should the data scientist use to deduplicate the orders using PySpark?
18 of 55.
An engineer has two DataFrames — df1 (small) and df2 (large). To optimize the join, the engineer uses a broadcast join:
from pyspark.sql.functions import broadcast
df_result = df2.join(broadcast(df1), on="id", how="inner")
What is the purpose of using broadcast() in this scenario?
A data engineer needs to persist a file-based data source to a specific location. However, by default, Spark writes to the warehouse directory (e.g., /user/hive/warehouse). To override this, the engineer must explicitly define the file path.
Which line of code ensures the data is saved to a specific location?
Options:
An MLOps engineer is building a Pandas UDF that applies a language model that translates English strings into Spanish. The initial code is loading the model on every call to the UDF, which is hurting the performance of the data pipeline.
The initial code is:

def in_spanish_inner(df: pd.Series) -> pd.Series:
model = get_translation_model(target_lang='es')
return df.apply(model)
in_spanish = sf.pandas_udf(in_spanish_inner, StringType())
How can the MLOps engineer change this code to reduce how many times the language model is loaded?
8 of 55.
A data scientist at a large e-commerce company needs to process and analyze 2 TB of daily customer transaction data. The company wants to implement real-time fraud detection and personalized product recommendations.
Currently, the company uses a traditional relational database system, which struggles with the increasing data volume and velocity.
Which feature of Apache Spark effectively addresses this challenge?
Given:
python
CopyEdit
spark.sparkContext.setLogLevel("
Which set contains the suitable configuration settings for Spark driver LOG_LEVELs?
What is the behavior for function date_sub(start, days) if a negative value is passed into the days parameter?
6 of 55.
Which components of Apache Spark’s Architecture are responsible for carrying out tasks when assigned to them?
A Spark developer is building an app to monitor task performance. They need to track the maximum task processing time per worker node and consolidate it on the driver for analysis.
Which technique should be used?
What is a feature of Spark Connect?
What is the benefit of Adaptive Query Execution (AQE)?
How can a Spark developer ensure optimal resource utilization when running Spark jobs in Local Mode for testing?
Options:
34 of 55.
A data engineer is investigating a Spark cluster that is experiencing underutilization during scheduled batch jobs.
After checking the Spark logs, they noticed that tasks are often getting killed due to timeout errors, and there are several warnings about insufficient resources in the logs.
Which action should the engineer take to resolve the underutilization issue?
16 of 55.
A data engineer is reviewing a Spark application that applies several transformations to a DataFrame but notices that the job does not start executing immediately.
Which two characteristics of Apache Spark's execution model explain this behavior? (Choose 2 answers)
37 of 55.
A data scientist is working with a Spark DataFrame called customerDF that contains customer information.
The DataFrame has a column named email with customer email addresses.
The data scientist needs to split this column into username and domain parts.
Which code snippet splits the email column into username and domain columns?
A data engineer has been asked to produce a Parquet table which is overwritten every day with the latest data. The downstream consumer of this Parquet table has a hard requirement that the data in this table is produced with all records sorted by the market_time field.
Which line of Spark code will produce a Parquet table that meets these requirements?
54 of 55.
What is the benefit of Adaptive Query Execution (AQE)?
Given the schema:

event_ts TIMESTAMP,
sensor_id STRING,
metric_value LONG,
ingest_ts TIMESTAMP,
source_file_path STRING
The goal is to deduplicate based on: event_ts, sensor_id, and metric_value.
Options:
A data engineer is working with a large JSON dataset containing order information. The dataset is stored in a distributed file system and needs to be loaded into a Spark DataFrame for analysis. The data engineer wants to ensure that the schema is correctly defined and that the data is read efficiently.
Which approach should the data scientist use to efficiently load the JSON data into a Spark DataFrame with a predefined schema?
11 of 55.
Which Spark configuration controls the number of tasks that can run in parallel on an executor?
A developer notices that all the post-shuffle partitions in a dataset are smaller than the value set for spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold.
Which type of join will Adaptive Query Execution (AQE) choose in this case?
30 of 55.
A data engineer is working on a num_df DataFrame and has a Python UDF defined as:
def cube_func(val):
return val * val * val
Which code fragment registers and uses this UDF as a Spark SQL function to work with the DataFrame num_df?
A developer is working with a pandas DataFrame containing user behavior data from a web application.
Which approach should be used for executing a groupBy operation in parallel across all workers in Apache Spark 3.5?
A)
Use the applylnPandas API
B)

C)

D)

A developer is running Spark SQL queries and notices underutilization of resources. Executors are idle, and the number of tasks per stage is low.
What should the developer do to improve cluster utilization?
A data scientist is working on a project that requires processing large amounts of structured data, performing SQL queries, and applying machine learning algorithms. The data scientist is considering using Apache Spark for this task.
Which combination of Apache Spark modules should the data scientist use in this scenario?
Options:
42 of 55.
A developer needs to write the output of a complex chain of Spark transformations to a Parquet table called events.liveLatest.
Consumers of this table query it frequently with filters on both year and month of the event_ts column (a timestamp).
The current code:
from pyspark.sql import functions as F
final = df.withColumn("event_year", F.year("event_ts")) \
.withColumn("event_month", F.month("event_ts")) \
.bucketBy(42, ["event_year", "event_month"]) \
.saveAsTable("events.liveLatest")
However, consumers report poor query performance.
Which change will enable efficient querying by year and month?
A data engineer needs to write a DataFrame df to a Parquet file, partitioned by the column country, and overwrite any existing data at the destination path.
Which code should the data engineer use to accomplish this task in Apache Spark?
32 of 55.
A developer is creating a Spark application that performs multiple DataFrame transformations and actions. The developer wants to maintain optimal performance by properly managing the SparkSession.
How should the developer handle the SparkSession throughout the application?
3 of 55. A data engineer observes that the upstream streaming source feeds the event table frequently and sends duplicate records. Upon analyzing the current production table, the data engineer found that the time difference in the event_timestamp column of the duplicate records is, at most, 30 minutes.
To remove the duplicates, the engineer adds the code:
df = df.withWatermark("event_timestamp", "30 minutes")
What is the result?
Given the code fragment:
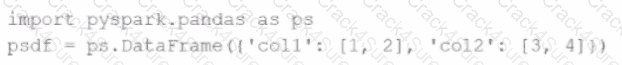
import pyspark.pandas as ps
psdf = ps.DataFrame({'col1': [1, 2], 'col2': [3, 4]})
Which method is used to convert a Pandas API on Spark DataFrame (pyspark.pandas.DataFrame) into a standard PySpark DataFrame (pyspark.sql.DataFrame)?
The following code fragment results in an error:
@F.udf(T.IntegerType())
def simple_udf(t: str) -> str:
return answer * 3.14159
Which code fragment should be used instead?
3 Months Free Update
3 Months Free Update
3 Months Free Update

TESTED 05 Mar 2026