We at Crack4sure are committed to giving students who are preparing for the Google Professional-Cloud-DevOps-Engineer Exam the most current and reliable questions . To help people study, we've made some of our Google Cloud Certified - Professional Cloud DevOps Engineer Exam exam materials available for free to everyone. You can take the Free Professional-Cloud-DevOps-Engineer Practice Test as many times as you want. The answers to the practice questions are given, and each answer is explained.
You recently created a Cloud Build pipeline for deploying Terraform code stored in a GitHub repository. You make Terraform code changes in short-lived branches and sometimes use tags during development. You tag releases with a semantic version when they are ready for deployment. You require your pipeline to apply the Terraform code whenever there is a new release, and you need to minimize operational overhead. What should you do?
You are building the Cl/CD pipeline for an application deployed to Google Kubernetes Engine (GKE) The application is deployed by using a Kubernetes Deployment, Service, and Ingress The application team asked you to deploy the application by using the blue'green deployment methodology You need to implement the rollback actions What should you do?
Your team is building a service that performs compute-heavy processing on batches of data The data is processed faster based on the speed and number of CPUs on the machine These batches of data vary in size and may arrive at any time from multiple third-party sources You need to ensure that third partiesare able to upload their data securely. You want to minimize costs while ensuring that the data is processed as quickly as possible What should you do?
Your company wants to implement a CD pipeline in Cloud Deploy for a web service deployed to GKE. The web service currently does not have any automated testing. The Quality Assurance team must manually verify any new releases of the web service before any production traffic is processed. You need to design the CD pipeline. What should you do?
Your product is currently deployed in three Google Cloud Platform (GCP) zones with your users divided between the zones. You can fail over from one zone to another, but it causes a 10-minute service disruption for the affected users. You typically experience a database failure once per quarter and can detect it within five minutes. You are cataloging the reliability risks of a new real-time chat feature for your product. You catalog the following information for each risk:
• Mean Time to Detect (MUD} in minutes
• Mean Time to Repair (MTTR) in minutes
• Mean Time Between Failure (MTBF) in days
• User Impact Percentage
The chat feature requires a new database system that takes twice as long to successfully fail over between zones. You want to account for the risk of the new database failing in one zone. What would be the values for the risk of database failover with the new system?
You are managing an application that runs in Compute Engine The application uses a custom HTTP server to expose an API that is accessed by other applications through an internal TCP/UDP load balancer A firewall rule allows access to the API port from 0.0.0-0/0. You need to configure Cloud Logging to log each IP address that accesses the API by using the fewest number of steps What should you do Bret?
You have an application running in Google Kubernetes Engine. The application invokes multiple services per request but responds too slowly. You need to identify which downstream service or services are causing the delay. What should you do?
Your development team has created a new version of their service’s API. You need to deploy the new versions of the API with the least disruption to third-party developers and end users of third-party installed applications. What should you do?
You are leading a DevOps project for your organization. The DevOps team is responsible for managing the service infrastructure and being on-call for incidents. The Software Development team is responsible for writing, submitting, and reviewing code. Neither team has any published SLOs. You want to design a new joint-ownership model for a service between the DevOps team and the Software Development team. Which responsibilities should be assigned to each team in the new joint-ownership model?
You are running an application in a virtual machine (VM) using a custom Debian image. The image has the Stackdriver Logging agent installed. The VM has the cloud-platform scope. The application is logging information via syslog. You want to use Stackdriver Logging in the Google Cloud Platform Console to visualize the logs. You notice that syslog is not showing up in the "All logs" dropdown list of the Logs Viewer. What is the first thing you should do?
You recently deployed your application in Google Kubernetes Engine (GKE) and now need to release a new version of the application You need the ability to instantly roll back to the previous version of the application in case there are issues with the new version Which deployment model should you use?
You are troubleshooting a failed deployment in your CI/CD pipeline. The deployment logs indicate that the application container failed to start due to a missing environment variable. You need to identify the root cause and implement a solution within your CI/CD workflow to prevent this issue from recurring. What should you do?
You are developing a strategy for monitoring your Google Cloud Platform (GCP) projects in production using Stackdriver Workspaces. One of the requirements is to be able to quickly identify and react to production environment issues without false alerts from development and staging projects. You want to ensure that you adhere to the principle of least privilege when providing relevant team members with access to Stackdriver Workspaces. What should you do?
You are responding to a high-priority incident where a critical, user-facing payment service is experiencing a 50% error rate. The cause is a non-critical, batch analytics Dataflow pipeline flooding a shared Memorystore for Redis instance with writes, which has spiked read latency for the payment service. A full rollback of the Dataflow pipeline's deployment will take 15 minutes to complete through your CI/CD process. You need to restore the payment service as quickly as possible. What should you do?
Your company runs services on Google Cloud. Each team runs their applications in a dedicated project. New teams and projects are created regularly. Your security team requires that all logs are processed by a security information and event management (SIEM) system. The SIEM ingests logs by using Pub/Sub. You must ensure that all existing and future logs are scanned by the SIEM. What should you do?
Your organization recently adopted a container-based workflow for application development. Your team develops numerous applications that are deployed continuously through an automated build pipeline to the production environment. A recent security audit alerted your team that the code pushed to production could contain vulnerabilities and that the existing tooling around virtual machine (VM) vulnerabilities no longer applies to the containerized environment. You need to ensure the security and patch level of all code running through the pipeline. What should you do?
You have an application that runs on Cloud Run. You want to use live production traffic to test a new version of the application while you let the quality assurance team perform manual testing. You want to limit the potential impact of any issues while testing the new version, and you must be able to roll back to a previous version of the application if needed. How should you deploy the new version?
Choose 2 answers
You are running a real-time gaming application on Compute Engine that has a production and testing environment. Each environment has their own Virtual Private Cloud (VPC) network. The application frontend and backend servers are located on different subnets in the environment's VPC. You suspect there is a malicious process communicating intermittently in your production frontend servers. You want to ensure that network traffic is captured for analysis. What should you do?
You are the Site Reliability Engineer responsible for managing your company's data services and products. You regularly navigate operational challenges, such as unpredictable data volume and high cost, with your company's data ingestion processes. You recently learned that a new data ingestion product will be developed in Google Cloud. You need to collaborate with the product development team to provide operational input on the new product. What should you do?
Your company experiences bugs, outages, and slowness in its production systems. Developers use the production environment for new feature development and bug fixes. Configuration and experiments are done in the production environment, causing outages for users. Testers use the production environmentfor load testing, which often slows the production systems. You need to redesign the environment to reduce the number of bugs and outages in production and to enable testers to load test new features. What should you do?
You support a service that recently had an outage. The outage was caused by a new release that exhausted the service memory resources. You rolled back the release successfully to mitigate the impact on users. You are now in charge of the post-mortem for the outage. You want to follow Site Reliability Engineering practices when developing the post-mortem. What should you do?
Your company operates in a highly regulated domain. Your security team requires that only trusted container images can be deployed to Google Kubernetes Engine (GKE). You need to implement a solution that meets the requirements of the security team, while minimizing management overhead. What should you do?
You are using Stackdriver to monitor applications hosted on Google Cloud Platform (GCP). You recently deployed a new application, but its logs are not appearing on the Stackdriver dashboard.
You need to troubleshoot the issue. What should you do?
You use Spinnaker to deploy your application and have created a canary deployment stage in the pipeline. Your application has an in-memory cache that loads objects at start time. You want to automate the comparison of the canary version against the production version. How should you configure the canary analysis?
Your applications performance in Google Cloud has degraded since the last release You suspect that downstream dependencies might be causing some requests to take longer to complete You need to investigate the issue with your application to determine the cause What should you do?
Your organization has a containerized web application that runs on-premises As part of the migration plan to Google Cloud you need to select a deployment strategy and platform that meets the following acceptance criteria
1 The platform must be able to direct traffic from Android devices to an Android-specific microservice
2 The platform must allow for arbitrary percentage-based traffic splitting
3 The deployment strategy must allow for continuous testing of multiple versions of any microservice
What should you do?
You are configuring the frontend tier of an application deployed in Google Cloud The frontend tier is hosted in ngmx and deployed using a managed instance group with an Envoy-based external HTTP(S) load balancer in front The application is deployed entirely within the europe-west2 region: and only serves users based in the United Kingdom. You need to choose the most cost-effective network tier and load balancing configuration What should you use?
You are implementing a CI'CD pipeline for your application in your company s multi-cloud environment Your application is deployed by using custom Compute Engine images and the equivalent in other cloud providers You need to implement a solution that will enable you to build and deploy the images to your current environment and is adaptable to future changes Which solution stack should you use'?
Your company stores a large volume of infrequently used data in Cloud Storage. The projects in your company's CustomerService folder access Cloud Storage frequently, but store very little data. You want to enable Data Access audit logging across the company to identify data usage patterns. You need to exclude the CustomerService folder projects from Data Access audit logging. What should you do?
You are designing a new multi-tenant Google Kubernetes Engine (GKE) cluster for a customer. Your customer is concerned with the risks associated with long-lived credentials use. The customer requires that each GKE workload has the minimum Identity and Access Management (IAM) permissions set following the principle of least privilege (PoLP). You need to design an IAM impersonation solution while following Google-recommended practices. What should you do?
You have a pool of application servers running on Compute Engine. You need to provide a secure solution that requires the least amount of configuration and allows developers to easily access application logs for troubleshooting. How would you implement the solution on GCP?
You support a service with a well-defined Service Level Objective (SLO). Over the previous 6 months, your service has consistently met its SLO and customer satisfaction has been consistently high. Most of your service’s operations tasks are automated and few repetitive tasks occur frequently. You want to optimize the balance between reliability and deployment velocity while following site reliability engineering best practices. What should you do? (Choose two.)
You support a production service that runs on a single Compute Engine instance. You regularly need to spend time on recreating the service by deleting the crashing instance and creating a new instance based on the relevant image. You want to reduce the time spent performing manual operations while following Site Reliability Engineering principles. What should you do?
As part of your company's initiative to shift left on security, the infoSec team is asking all teams to implement guard rails on all the Google Kubernetes Engine (GKE) clusters to only allow the deployment of trusted and approved images You need to determine how to satisfy the InfoSec teams goal of shifting left on security. What should you do?
You support an application running on App Engine. The application is used globally and accessed from various device types. You want to know the number of connections. You are using Stackdriver Monitoring for App Engine. What metric should you use?
You are the Operations Lead for an ongoing incident with one of your services. The service usually runs at around 70% capacity. You notice that one node is returning 5xx errors for all requests. There has also been a noticeable increase in support cases from customers. You need to remove the offending node from the load balancer pool so that you can isolate and investigate the node. You want to follow Google-recommended practices to manage the incident and reduce the impact on users. What should you do?
You support a multi-region web service running on Google Kubernetes Engine (GKE) behind a Global HTTP'S Cloud Load Balancer (CLB). For legacy reasons, user requests first go through a third-party Content Delivery Network (CDN). which then routes traffic to the CLB. You have already implemented an availability Service Level Indicator (SLI) at the CLB level. However, you want to increase coverage in case of a potential load balancer misconfiguration. CDN failure, or other global networking catastrophe. Where should you measure this new SLI?
Choose 2 answers
You are deploying an application to Cloud Run. The application requires a password to start. Your organization requires that all passwords are rotated every 24 hours, and your application must have the latest password. You need to deploy the application with no downtime. What should you do?
You are deploying an application that needs to access sensitive information. You need to ensure that this information is encrypted and the risk of exposure is minimal if a breach occurs. What should you do?
You are developing a Node.js utility on a workstation in Cloud Workstations by using Code OSS. The utility is a simple web page, and you have already confirmed that all necessary firewall rules are in place. You tested the application by starting it on port 3000 on your workstation in Cloud Workstations, but you need to be able to access the web page from your local machine. You need to follow Google-recommended security practices. What should you do?
You support a high-traffic web application and want to ensure that the home page loads in a timely manner. As a first step, you decide to implement a Service Level Indicator (SLI) to represent home page request latency with an acceptable page load time set to 100 ms. What is the Google-recommended way of calculating this SLI?
Your company is creating a new cloud-native Google Cloud organization. You expect this Google Cloud organization to first be used by a small number of departments and then expand to be used by a large number of departments. Each department has a large number of applications varying in size. You need to design the VPC network architecture. Your solution must minimize the amount of management required while remaining flexible enough for development teams to quickly adapt to their evolving needs. What should you do?
As a Site Reliability Engineer, you support an application written in GO that runs on Google Kubernetes Engine (GKE) in production. After releasing a new version Of the application, you notice the applicationruns for about 15 minutes and then restarts. You decide to add Cloud Profiler to your application and now notice that the heap usage grows constantly until the application restarts. What should you do?
You are running a web application that connects to an AlloyDB cluster by using a private IP address in your default VPC. You need to run a database schema migration in your CI/CD pipeline by using Cloud Build before deploying a new version of your application. You want to follow Google-recommended security practices. What should you do?
You are running an application on Compute Engine and collecting logs through Stackdriver. You discover that some personally identifiable information (Pll) is leaking into certain log entry fields. All Pll entries begin with the text userinfo. You want to capture these log entries in a secure location for later review and prevent them from leaking to Stackdriver Logging. What should you do?
You are managing the production deployment to a set of Google Kubernetes Engine (GKE) clusters. You want to make sure only images which are successfully built by your trusted CI/CD pipeline are deployed to production. What should you do?
You have a set of applications running on a Google Kubernetes Engine (GKE) cluster, and you are using Stackdriver Kubernetes Engine Monitoring. You are bringing a new containerized application required by your company into production. This application is written by a third party and cannot be modified or reconfigured. The application writes its log information to /var/log/app_messages.log, and you want to send these log entries to Stackdriver Logging. What should you do?
Your team is running microservices in Google Kubernetes Engine (GKE) You want to detect consumption of an error budget to protect customers and define release policies What should you do?
You manage several production systems that run on Compute Engine in the same Google Cloud Platform (GCP) project. Each system has its own set of dedicated Compute Engine instances. You want to know how must it costs to run each of the systems. What should you do?
Your company runs applications in Google Kubernetes Engine (GKE). Several applications rely on ephemeral volumes. You noticed some applications were unstable due to the DiskPressure node condition on the worker nodes. You need
to identify which Pods are causing the issue, but you do not have execute access to workloads and nodes. What should you do?
You have a CI/CD pipeline that uses Cloud Build to build new Docker images and push them to Docker Hub. You use Git for code versioning. After making a change in the Cloud Build YAML configuration, you notice that no new artifacts are being built by the pipeline. You need to resolve the issue following Site Reliability Engineering practices. What should you do?
You are currently planning how to display Cloud Monitoring metrics for your organization's Google Cloud projects. Your organization has three folders and six projects:
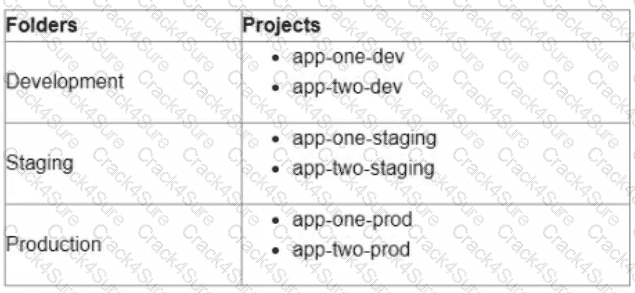
You want to configure Cloud Monitoring dashboards lo only display metrics from the projects within one folder You need to ensure that the dashboards do not display metrics from projects in the other folders You want to follow Google-recommended practices What should you do?
Your team is designing a new application for deployment both inside and outside Google Cloud Platform (GCP). You need to collect detailed metrics such as system resource utilization. You want to use centralized GCP services while minimizing the amount of work required to set up this collection system. What should you do?
Your application images are built and pushed to Google Container Registry (GCR). You want to build an automated pipeline that deploys the application when the image is updated while minimizing the development effort. What should you do?
Your team deploys applications to three Google Kubernetes Engine (GKE) environments development staging and production You use GitHub reposrtones as your source of truth You need to ensure that the three environments are consistent You want to follow Google-recommended practices to enforce and install network policies and a logging DaemonSet on all the GKE clusters in those environments What should you do?
3 Months Free Update
3 Months Free Update
3 Months Free Update

TESTED 16 Jul 2026