We at Crack4sure are committed to giving students who are preparing for the Microsoft DP-100 Exam the most current and reliable questions . To help people study, we've made some of our Designing and Implementing a Data Science Solution on Azure exam materials available for free to everyone. You can take the Free DP-100 Practice Test as many times as you want. The answers to the practice questions are given, and each answer is explained.
You manage an Azure At Foundry project.
You are implementing a RAG solution. The documents contain tables and images that must be broken into semantically relevant chunks.
You need to generate textual representations of images and tables to be used as chunks.
Which two chunking approaches should you use? Each correct answer presents a complete solution. Choose two.
NOTE: Each correct selection is worth one point.
You manage an Azure Machine Learning workspace.
You train a model interactively with a Jupyter Notebook in the workspace During training, a dataset is created with accuiacy and loss metrics for each epoch.
You need to configure model tracking with MLflow to log the dataset created during the training.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

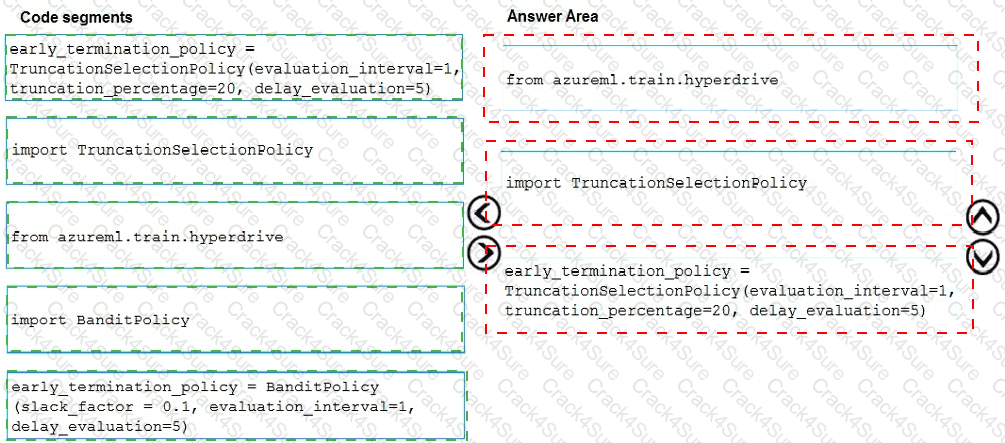
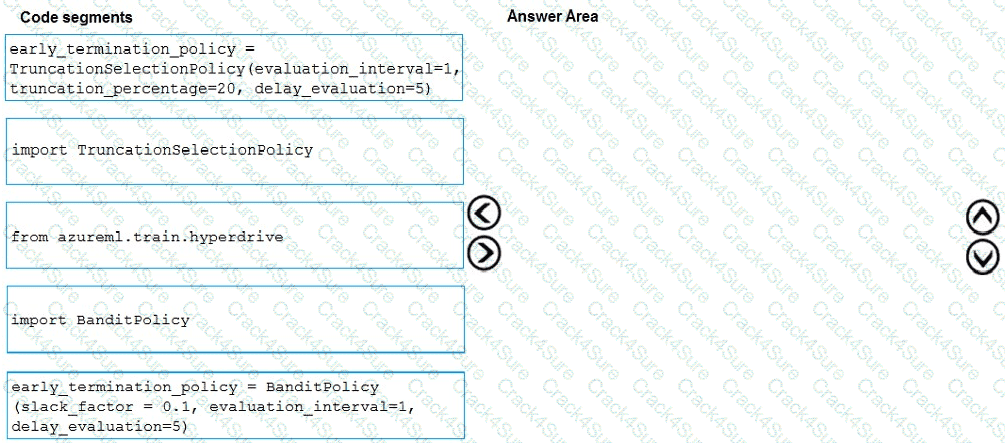
You need to implement early stopping criteria as suited in the model training requirements.
Which three code segments should you use to develop the solution? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
You use the Azure Machine Learning Python SDK to create a batch inference pipeline.
You must publish the batch inference pipeline so that business groups in your organization can use the pipeline. Each business group must be able to specify a different location for the data that the pipeline submits to the model for scoring.
You need to publish the pipeline.
What should you do?
You have the following Azure subscriptions and Azure Machine Learning service workspaces:

You need to obtain a reference to the mi-protect workspace
Solution: Run the following Python code.
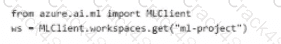
Does the solution meet the goal?
You have the following Azure subscriptions and Azure Machine Learning service workspaces:

You need to obtain a reference to the ml-project workspace.
Solution: Run the following Python code:

Does the solution meet the goal?
You manage an Azure Machine Learning workspace. The Pylhon scrip! named scriptpy reads an argument named training_data. The trainlng.data argument specifies the path to the training data in a file named datasetl.csv.
You plan to run the scriptpy Python script as a command job that trains a machine learning model.
You need to provide the command to pass the path for the datasct as a parameter value when you submit the script as a training job.
Solution: python train.py --training_data training_data
Does the solution meet the goal?
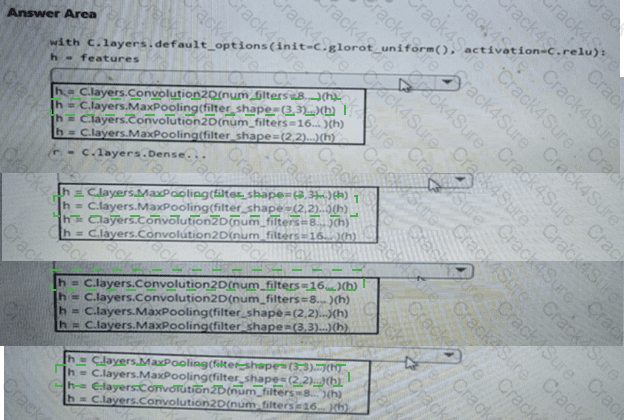
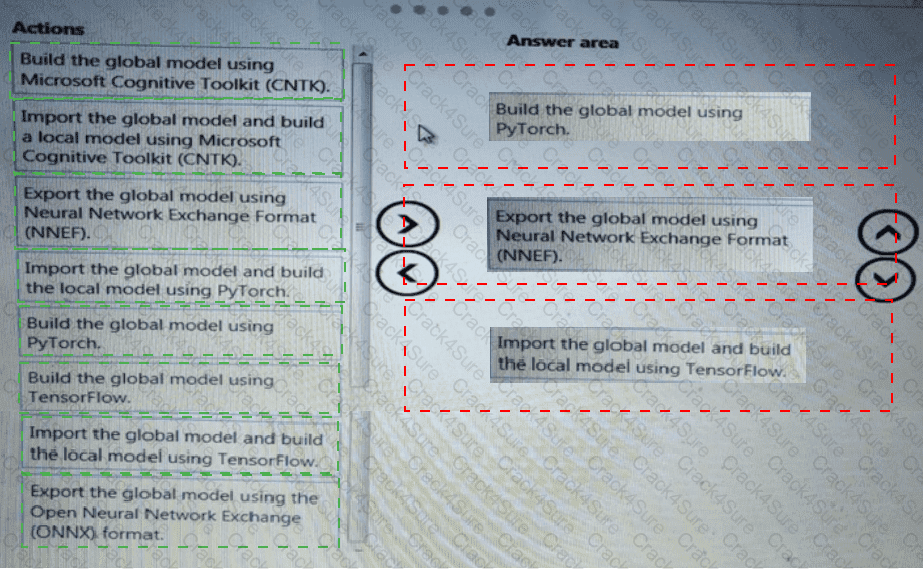
You need to build a feature extraction strategy for the local models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You have an Azure Machine Learning workspace. You are connecting an Azure Data Lake Storage Gen2 account to the workspace as a data store. You need to authorize access from the workspace to the Azure Data Lake Storage Gen2 account.
What should you use?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Python script named train.py in a local folder named scripts. The script trains a regression model by using scikit-learn. The script includes code to load a training data file which is also located in the scripts folder.
You must run the script as an Azure ML experiment on a compute cluster named aml-compute.
You need to configure the run to ensure that the environment includes the required packages for model training. You have instantiated a variable named aml-compute that references the target compute cluster.
Solution: Run the following code:

Does the solution meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to use a Python script to run an Azure Machine Learning experiment. The script creates a reference to the experiment run context, loads data from a file, identifies the set of unique values for the label column, and completes the experiment run:

The experiment must record the unique labels in the data as metrics for the run that can be reviewed later.
You must add code to the script to record the unique label values as run metrics at the point indicated by the comment.
Solution: Replace the comment with the following code:
run.log_list( ' Label Values ' , label_vals)
Does the solution meet the goal?
You are authoring a notebook in Azure Machine Learning studio.
You must install packages from the notebook into the currently running kernel. The installation must be limited to the currently running kernel only.
You need to install the packages.
Which magic function should you use?
You manage an Azure Machine Learning workspace. The development environment for managing the workspace is configured to use Python SDK v2 in Azure Machine Learning Notebooks
A Synapse Spark Compute is currently attached and uses system-assigned identity
You need to use Python code to update the Synapse Spark Compute to use a user-assigned identity.
Solution: Create an instance of the MICIient class.
Does the solution meet the goal?
You manage an Azure Machine Learning workspace.
An MLflow model is already registered. You plan to customize how the deployment does inference. You need to deploy the MLflow model to a batch endpoint for batch inferencing. What should you create first?
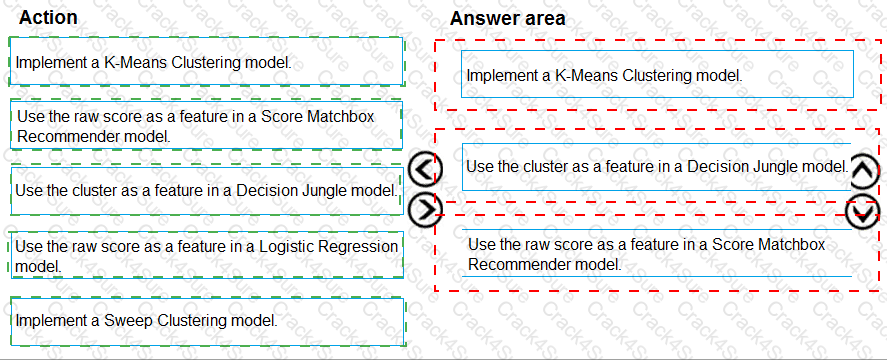
You need to define a modeling strategy for ad response.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
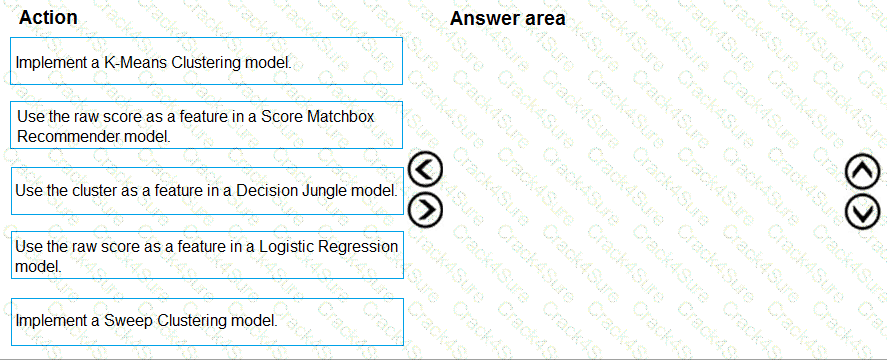
You need to resolve the local machine learning pipeline performance issue. What should you do?
You need to select an environment that will meet the business and data requirements.
Which environment should you use?
You use Azure Machine Learning to train a model. You must use Bayesian sampling to tune hyperparameters. You need to select a ieaming_rate parameter distribution.
Which two distributions can you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
You are creating a classification model for a banking company to identify possible instances of credit card fraud. You plan to create the model in Azure Machine Learning by using automated machine learning.
The training dataset that you are using is highly unbalanced.
You need to evaluate the classification model.
Which primary metric should you use?
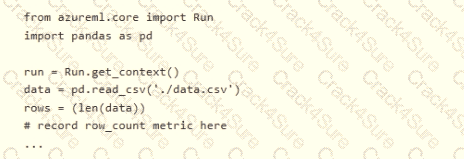
You need to record the row count as a metric named row_count that can be returned using the get_metrics method of the Run object after the experiment run completes. Which code should you use?
You manage an Azure AI Foundry project in your subscription. You deploy a gpt-4o model. You must test the model before you use it in an existing front-end application. You need to adjust the parameters to get more creative responses.
Solution: Increase Temperature.
Does the solution meet the goal?
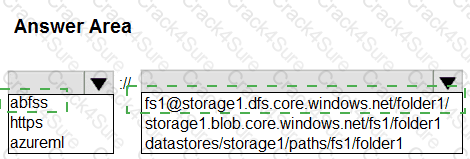
You create an Azure Data Lake Storage Gen2 stowage account named storage1 containing a file system named fsi and a folder named folder1.
The contents of folder1 must be accessible from jobs on compute targets in the Azure Machine Learning workspace.
You need to construct a URl to reference folder1.
How should you construct the URI? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are analyzing a numerical dataset which contain missing values in several columns.
You must clean the missing values using an appropriate operation without affecting the dimensionality of the feature set.
You need to analyze a full dataset to include all values.
Solution: Use the last Observation Carried Forward (IOCF) method to impute the missing data points.
Does the solution meet the goal?
You manage an Azure Machine Learning workspace named workspace1 with a compute instance named compute1. You connect to compute! by using a terminal window from wofkspace1. You create a file named " requirements.txt " containing Python dependencies to include Jupyler.
You need to add a new Jupyter kernel to compute1.
Which four commands should you use? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

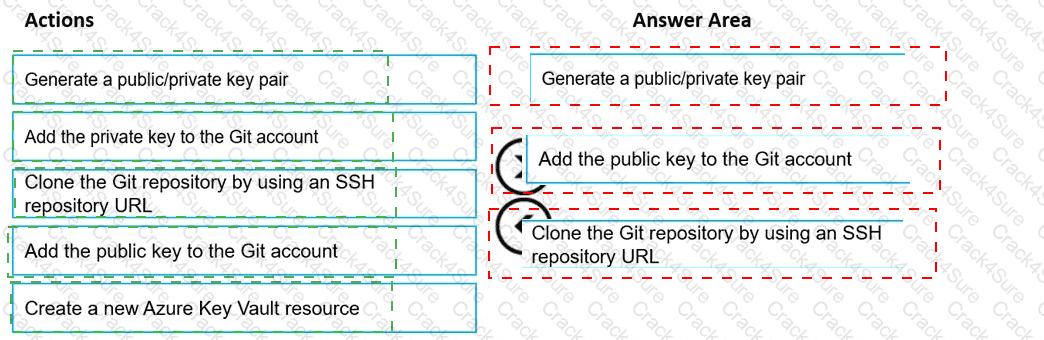
You are using a Git repository to track work in an Azure Machine Learning workspace.
You need to authenticate a Git account by using SSH.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
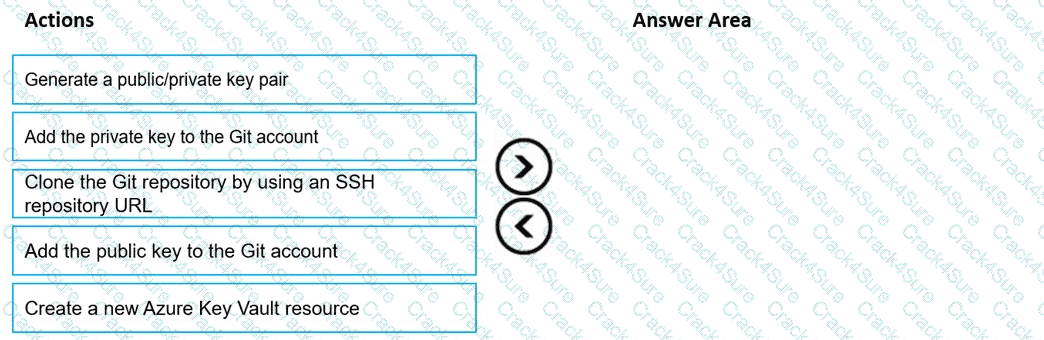
You manage an Azure Machine Learning workspace. You plan to import data from Azure Data Lake Storage Gen2. You need to build a URI that represents the storage location. Which protocol should you use?
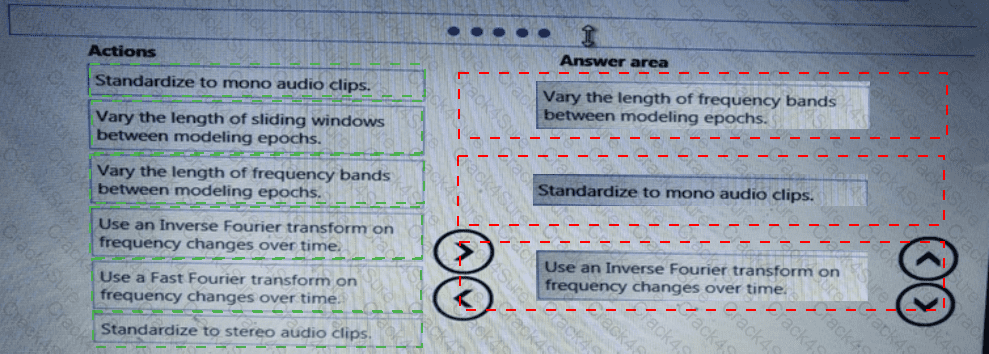
You need to implement a feature engineering strategy for the crowd sentiment local models.
What should you do?
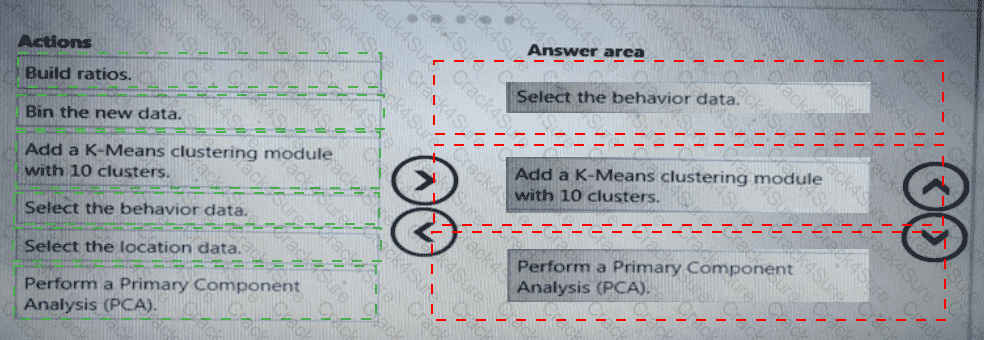
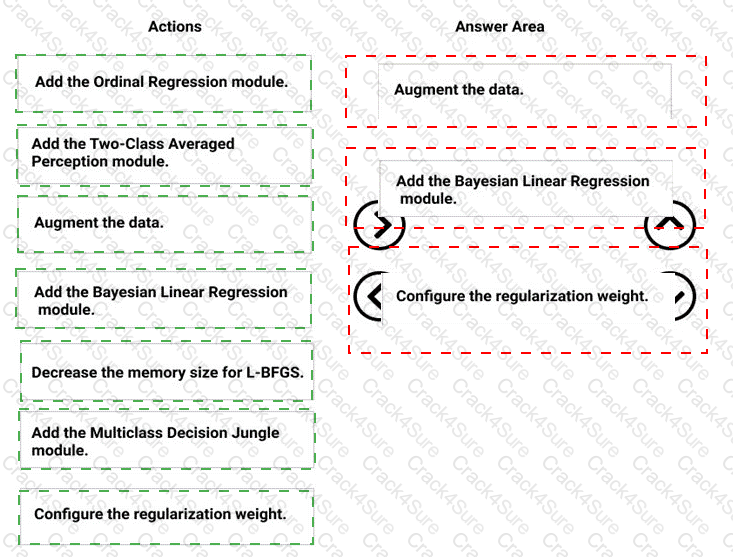
You need to implement a model development strategy to determine a user’s tendency to respond to an ad.
Which technique should you use?
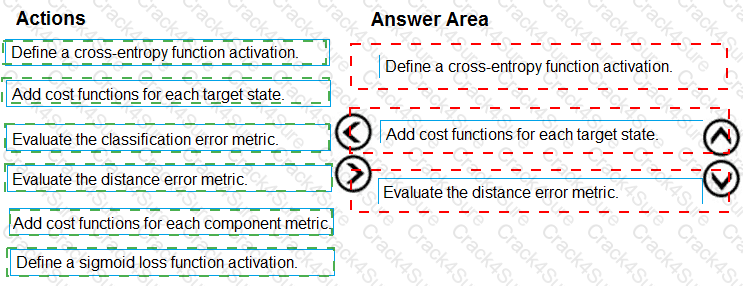
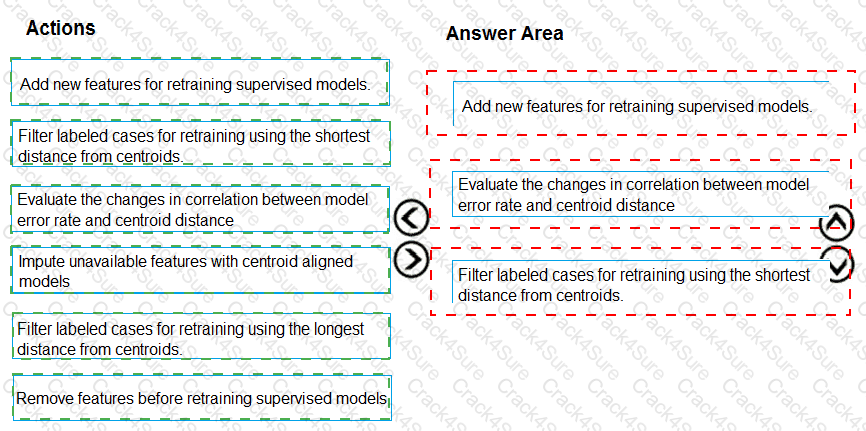
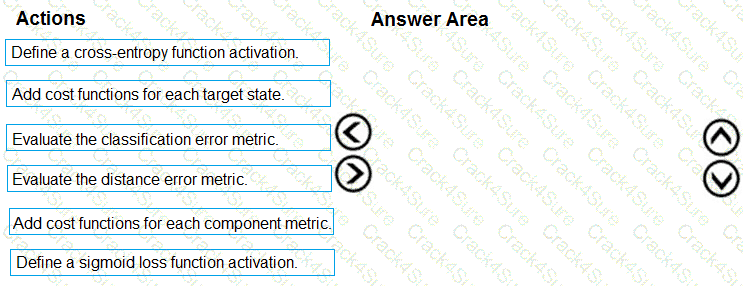
You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
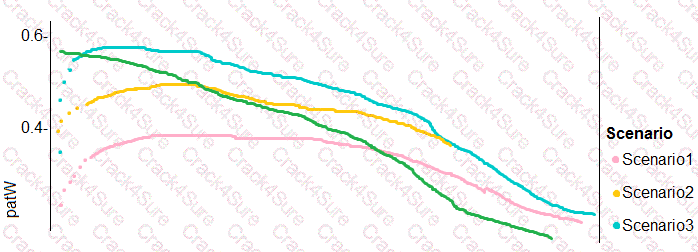
You need to implement a new cost factor scenario for the ad response models as illustrated in the
performance curve exhibit.
Which technique should you use?
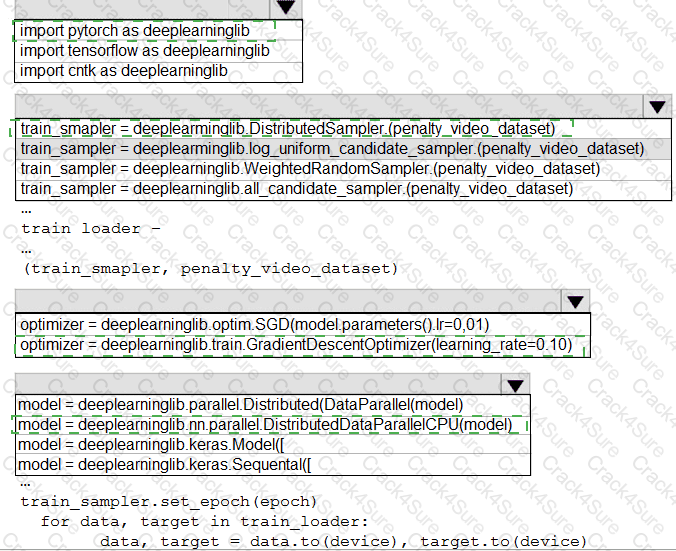
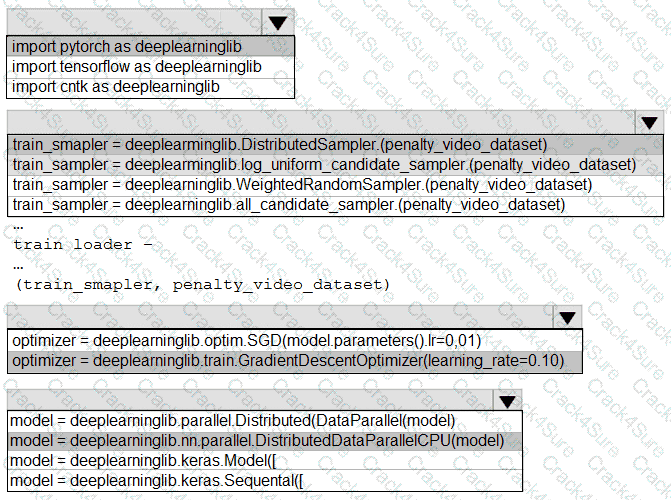
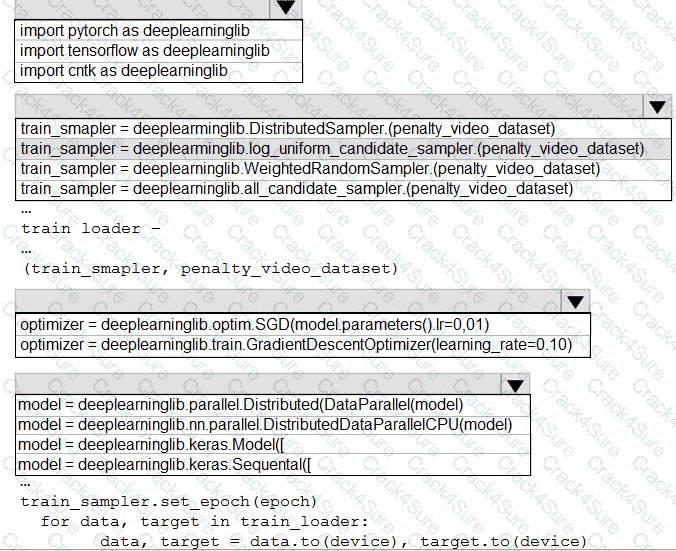
You need to use the Python language to build a sampling strategy for the global penalty detection models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
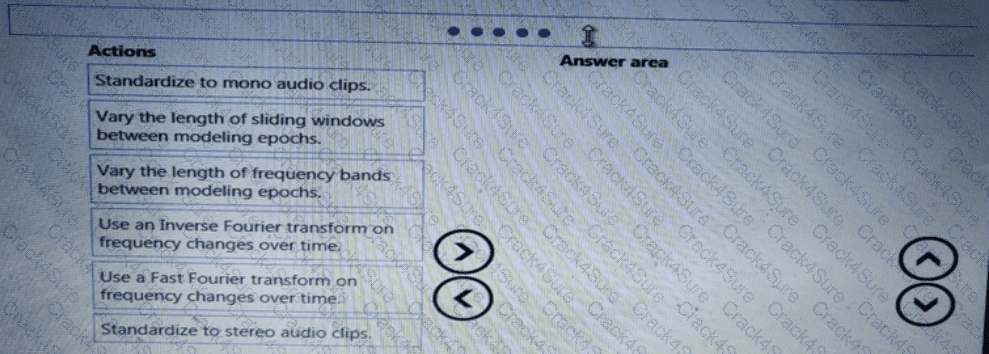
You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
You need to modify the inputs for the global penalty event model to address the bias and variance issue.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

You train and register an Azure Machine Learning model
You plan to deploy the model to an online endpoint
You need to ensure that applications will be able to use the authentication method with a non-expiring artifact to access the model.
Solution:
Create a managed online endpoint with the default authentication settings. Deploy the model to the online endpoint.
Does the solution meet the goal?
You need to correct the model fit issue.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

You create a new Azure Machine Learning workspace with a compute cluster.
You need to create the compute cluster asynchronously by using the Azure Machine Learning Python SDK v2.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point

You manage an Azure Machine Learning workspace. You develop a regression model training pipeline by using Notebooks. You need to determine the appropriate evaluation metric for the experiment.
Which two metrics should you choose? Each correct answer presents a complete solution. Choose two. NOTE: Each correct selection is worth one point.
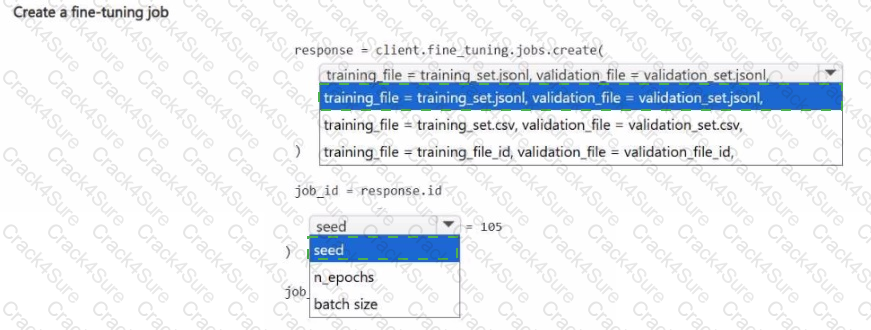
You manage an Azure Al Foundry project.
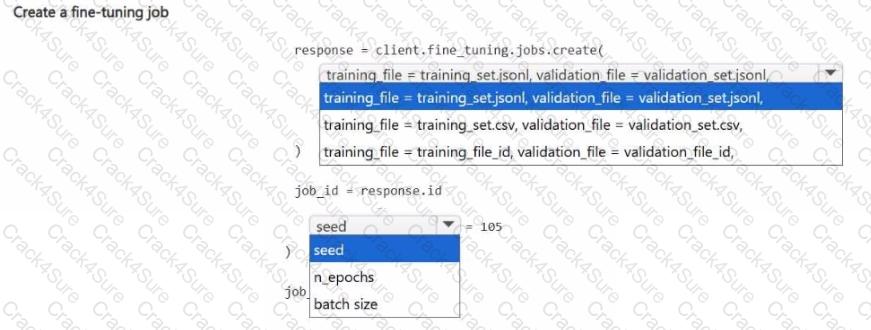
You plan to fine-tune a base model by using pre-uploaded training and validation data. You must specify a hyperparameter to ensure the job is reproducible.
You need to submit the fine-tuning training job.
How should you complete the Python code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You are building a machine learning model for translating English language textual content into French
language textual content.
You need to build and train the machine learning model to learn the sequence of the textual content.
Which type of neural network should you use?
You plan to use a Data Science Virtual Machine (DSVM) with the open source deep learning frameworks Caffe2 and Theano. You need to select a pre configured DSVM to support the framework.
What should you create?
You manage an Azure Machine Learning workspace That has an Azure Machine Learning datastore.
Data must be loaded from the following sources:
• a credential-less Azure Blob Storage
• an Azure Data Lake Storage (ADLS) Gen 2 which is not a credential-less datastore
You need to define the authentication mechanisms to access data in the Azure Machine Learning datastore.
Which data access mechanism should you use? To answer, move the appropriate data access mechanisms to the correct storage types. You may use each data access mechanism once, more than once, or not at all. You may need to move the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

You create an Azure Machine Learning pipeline named pipeline 1 with two steps that contain Python scnpts. Data processed by the first step is passed to the second step.
You must update the content of the downstream data source of pipeline 1 and run the pipeline again.
You need to ensure the new run of pipeline 1 fully processes the updated content.
Solution: Change the value of the compute.target parameter of the PythonScriptStep object in the two steps.
Does the solution meet the goal '
You manage an Azure Machine Learning workspace. The Pylhon scrip! named scriptpy reads an argument named training_data. The trainlng.data argument specifies the path to the training data in a file named datasetl.csv.
You plan to run the scriptpy Python script as a command job that trains a machine learning model.
You need to provide the command to pass the path for the datasct as a parameter value when you submit the script as a training job.
Solution: python script.py –training_data ${{inputs,training_data}}
Does the solution meet the goal?
You are creating a new Azure Machine Learning pipeline using the designer.
The pipeline must train a model using data in a comma-separated values (CSV) file that is published on a
website. You have not created a dataset for this file.
You need to ingest the data from the CSV file into the designer pipeline using the minimal administrative effort.
Which module should you add to the pipeline in Designer?
You create an Azure Machine Learning workspace.
You need to detect data drift between a baseline dataset and a subsequent target dataset by using the DataDriftDetector class.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You create an Azure Machine Learning compute target named ComputeOne by using the STANDARD_D1 virtual machine image.
You define a Python variable named was that references the Azure Machine Learning workspace. You run the following Python code:
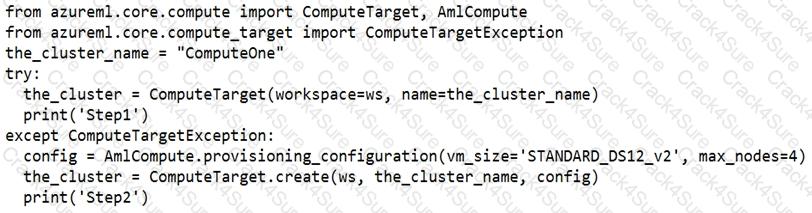
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

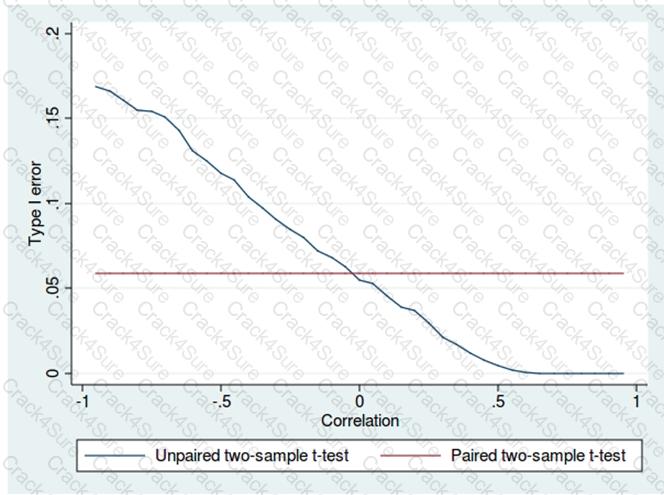
You are determining if two sets of data are significantly different from one another by using Azure Machine Learning Studio.
Estimated values in one set of data may be more than or less than reference values in the other set of data. You must produce a distribution that has a constant Type I error as a function of the correlation.
You need to produce the distribution.
Which type of distribution should you produce?
You manage an Azure Machine Learning workspace.
You need to define an environment from a Docker image by using the Azure Machine Learning Python SDK v2.
Which parameter should you use?

For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.

You plan to run a Python script as an Azure Machine Learning experiment.
The script contains the following code:
import os, argparse, glob
from azureml.core import Run
parser = argparse.ArgumentParser()
parser.add_argument( ' --input-data ' ,
type=str, dest= ' data_folder ' )
args = parser.parse_args()
data_path = args.data_folder
file_paths = glob.glob(data_path + " /*.jpg " )
You must specify a file dataset as an input to the script. The dataset consists of multiple large image files and must be streamed directly from its source.
You need to write code to define a ScriptRunConfig object for the experiment and pass the ds dataset as an argument.
Which code segment should you use?
You are analyzing a dataset containing historical data from a local taxi company. You arc developing a regression a regression model.
You must predict the fare of a taxi trip.
You need to select performance metrics to correctly evaluate the- regression model.
Which two metrics can you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
You write five Python scripts that must be processed in the order specified in Exhibit A – which allows the same modules to run in parallel, but will wait for modules with dependencies.
You must create an Azure Machine Learning pipeline using the Python SDK, because you want to script to create the pipeline to be tracked in your version control system. You have created five PythonScriptSteps and have named the variables to match the module names.
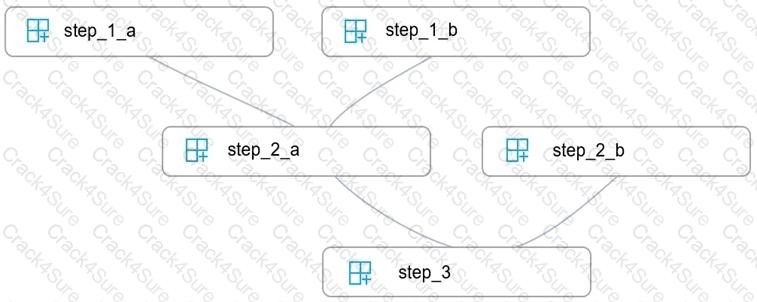
You need to create the pipeline shown. Assume all relevant imports have been done.
Which Python code segment should you use?

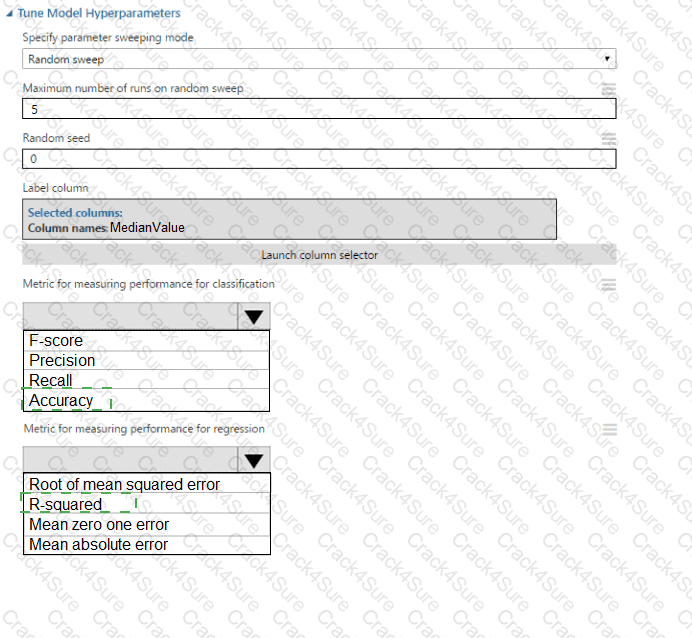
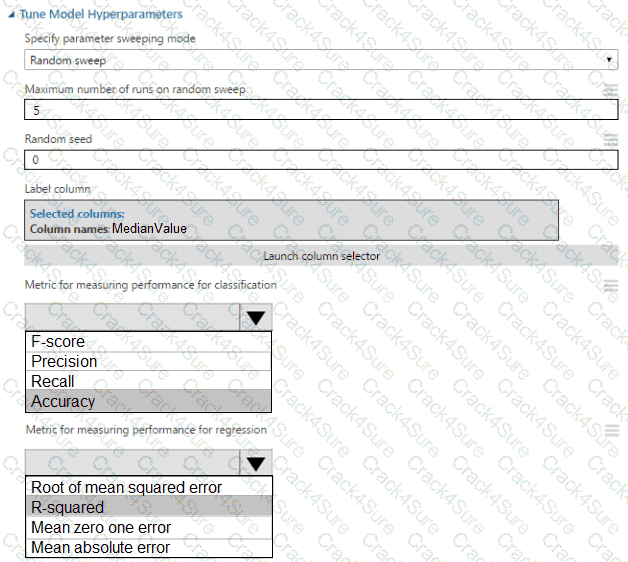
You need to set up the Permutation Feature Importance module according to the model training requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
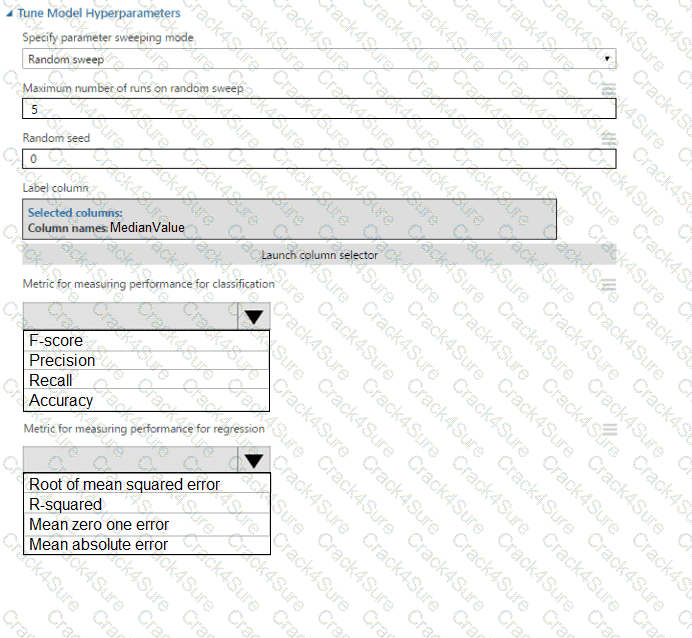
You need to select a feature extraction method.
Which method should you use?
You need to select a feature extraction method.
Which method should you use?
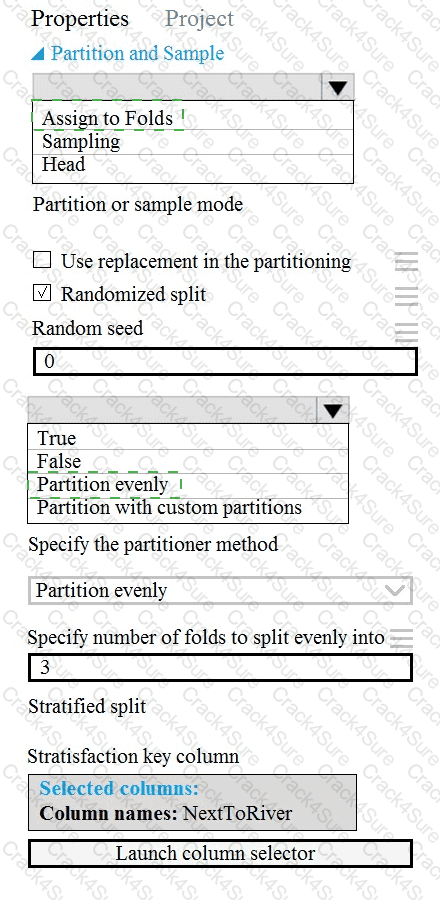
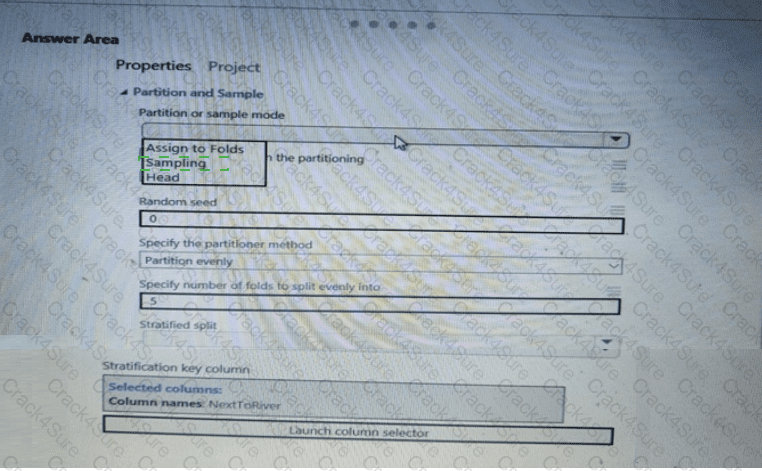
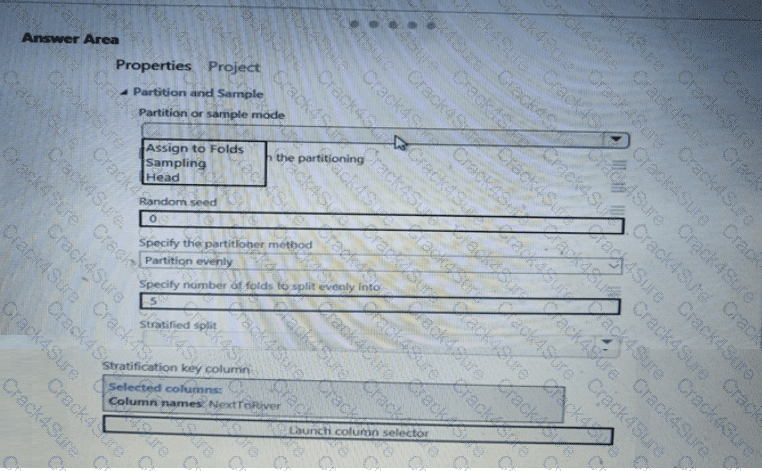
You need to identify the methods for dividing the data according to the testing requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

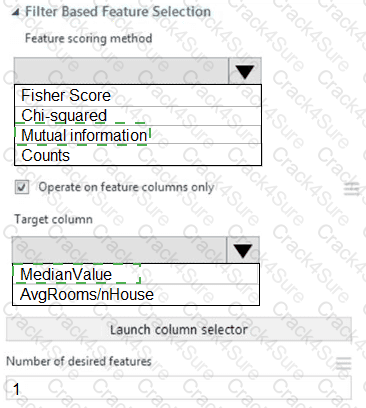
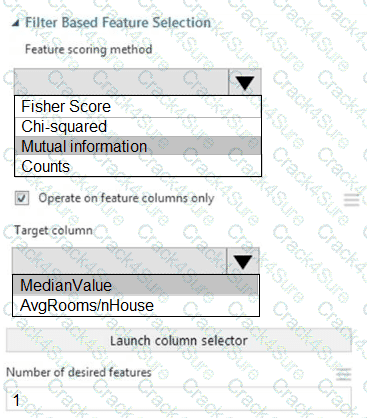
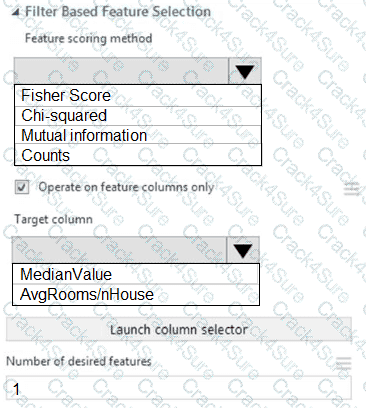
You need to configure the Feature Based Feature Selection module based on the experiment requirements and datasets.
How should you configure the module properties? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
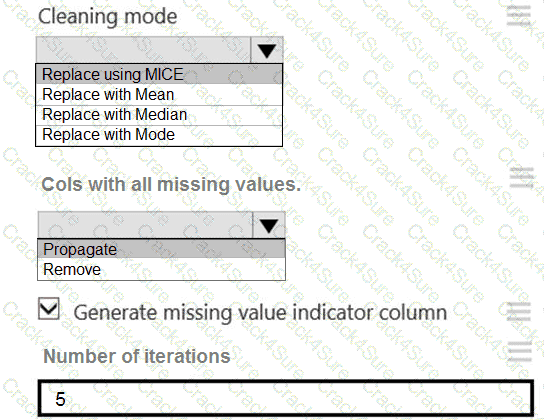
You need to replace the missing data in the AccessibilityToHighway columns.
How should you configure the Clean Missing Data module? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You need to identify the methods for dividing the data according, to the testing requirements.
Which properties should you select? To answer, select the appropriate option-, m the answer area. NOTE: Each correct selection is worth one point.
3 Months Free Update
3 Months Free Update
3 Months Free Update

TESTED 26 May 2026