We at Crack4sure are committed to giving students who are preparing for the Oracle 1z0-071 Exam the most current and reliable questions . To help people study, we've made some of our Oracle Database 12c SQL exam materials available for free to everyone. You can take the Free 1z0-071 Practice Test as many times as you want. The answers to the practice questions are given, and each answer is explained.
Which statement is true about the INTERSECT operator used in compound queries?
Which two statements are true about * _ TABLES views?
The CUSTOMERS table has a CUST_CREDT_LIMIT column of data type number.
Which two queries execute successfully?
In the PROMOTIONS table, the PROMO_ BEGIN_DATE column is of data type and the default date format is DD-MON-RR
Which two statements are true about expressions using PROMO_ BEGIN_DATE in a query?
Examine this partial command:
CREATE TABLE cust(
cust_id NUMBER(2),
credit_limit NUMBER(10)
ORGANIZATION EXTERNAL
Which two clauses are required for this command to execute successfully?
Which three statements are true about defining relations between tables in a relational database?

Which two queries will result in an error?
Which three statements are true about single-row functions?
Examine the description of the PRODUCT_ DETAILS table:

Which two statements are true?
Which three are true about multiple INSERT statements?
View the Exhibits and examine the structure of the COSTS and PROMOTIONS tables.
You want to display PROD IDS whose promotion cost is less than the highest cost PROD ID in a pro
motion time interval.
Examine this SQL statement:
SELECT prod id
FROM costs
WHERE promo id IN
(SELECT promo id
FROM promotions
WHERE promo_cost < ALL
(SELECT MAX (promo cost)
FROM promotions
GROUP BY (promo_end date-promo_begin_date)) );
What will be the result?
Which three are true about privileges?
Choose two
Examine the description of the PRODUCT DETALS table:

Which two are true about using constraints?
Which two queries return the string Hello! we're ready?
Examine this query which executes successfully:
SELECT job, deptno FROM emp
UNION ALL
SELECT job, deptno FROM jobs_ history;
What will be the result?
Which two statements are true about * _TABLES views?
Which three statements are true about an ORDER BY clause?
Examine the description of the EMPLOYEES table:
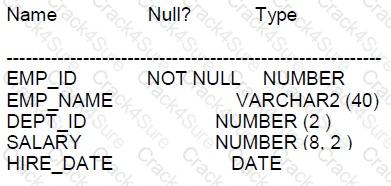
NLS_DATE FORMAT is DD-MON-RR.
Which two queries will execute successfully?
Which three statements are true regarding indexes?
Which two statements are true about Entity Relationships?
Examine the command to create the BOOKS table.
SQL> create table books(book id CHAR(6) PRIMARY KEY,
title VARCHAR2(100) NOT NULL,
publisher_id VARCHAR2(4)?
author_id VARCHAR2 (50));
The BOOK ID value 101 does not exist in the table.
Examine the SQL statement.
insert into books (book id title, author_id values
(‘101’?’LEARNING SQL’,’Tim Jones’)
Which statements is true about using functions in WHERE and HAVING?
Evaluate the following SQL statement
SQL>SELECT promo_id, prom _category FROM promotions
WHERE promo_category=’Internet’ ORDER BY promo_id
UNION
SELECT promo_id, promo_category FROM Pomotions
WHERE promo_category = ‘TV’
UNION
SELECT promoid, promocategory FROM promotions WHERE promo category=’Radio’
Which statement is true regarding the outcome of the above query?
The INVOICE table has a QTY_SOLD column of data type NUMBER and an INVOICE_DATE column of data type DATE NLS_DATE_FORMAT is set to DD-MON-RR.
Which two are true about data type conversions involving these columns in query expressions?
Examine the description of the EMPLOYEES table:
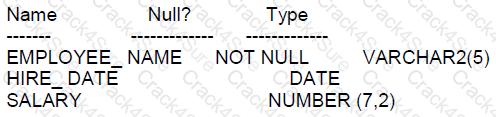
The session time zone is the same as the database server
Which two statements will list only the employees who have been working with the company for more than five years?
Examine this partial statement:
SELECT ename, sal,comm FROM emp
Now examine this output:

WHICH ORDER BY clause will generate the displayed output?
Which two statements about INVISIBLE indexes are true?
Which three statements are true about the Oracle join and ANSI Join syntax?
Examine the description of the ORDERS table:

Which three statements execute successfully?
Examine the description of the sales table.
The sales table has 55,000 rows.
Examine this statements:
Which two statements are true?
Examine the description of the PRODUCT_INFORMATION table:

Which three statements are true about GLOBAL TEMPORARY TABLES?
Which three statements are true about the DESCRIBE command?
Which two statements are true about outer Joins?
Which three actions can you perform by using the ALTER TABLE command?
Which three are true about scalar subquery expressions?
Examine the description of the BOOKS table:

The table has 100 rows.
Examine this sequence of statements issued in a new session;
INSERT INTO BOOKS VALUES (‘ADV112’ , ‘Adventures of Tom Sawyer’, NULL, NULL);
SAVEPOINT a;
DELETE from books;
ROLLBACK TO SAVEPOINT a;
ROLLBACK;
Which two statements are true?
Which two statements are true about transactions in the Oracle Database server?
Which two true about a sql statement using SET operations such as UNION?
Which three statements are true about inner and outer joins?
Examine the data in the EMP table:

You execute this query:
SELECT deptno AS "Department", AVG(sal) AS AverageSalary, MAX(sal) AS "Max Salary"
FROM emp
WHERE sal >= 12000
GROUP BY "Department "
ORDER BY AverageSalary;
Why does an error occur?
Which two statements are true about an Oracle database?
Which three are true about the CREATE TABLE command?
Which two statements are true about Oracle databases and SQL?
Which two queries execute successfully?
Examine the description of the PRODCTS table which contains data:

Which two are true?
Which two are true about virtual columns?
Table ORDER_ITEMS contains columns ORDER_ID, UNIT_PRICE and QUANTITY, of data type NUMBER
Statement 1:
SELECT MAX (unit price*quantity) "Maximum Order FROM order items;
Statement 2:
SELECT MAX (unit price*quantity "Maximum order" FROM order items GROUP BY order id;
Which two statements are true?
Examine the data in the PRODUCTS table:

Examine these queries:
1. SELECT prod name, prod list
FROM products
WHERE prod 1ist NOT IN(10?20) AND category _id=1;
2. SELECT prod name, | prod _ list
FROM products
WHERE prod list < > ANY (10?20) AND category _id= 1;
SELECT prod name, prod _ list
FROM products
WHERE prod_ list <> ALL (10? 20) AND category _ id= 1;
Which queries generate the same output?
Which two are true about the NVL, NVL2, and COALESCE functions?
Examine these requirements:
1. Display book titles for books purchased before January 17, 2007 costing less than 500 or more than 1000.
2. Sort the titles by date of purchase, starting with the most recently purchased book.
Which two queries can be used?
Examine the description of the EMPLOYEES table:

Which statement increases each employee's SALARY by the minimum SALARY for their DEPARTM
ENT_ID?
Which two statements are true about the SET VERIFY ON command?
Examine the description of the ENPLOYES table:

Which query requires explicit data type conversion?
Examine the data in the NEW_EMPLOYEES table:
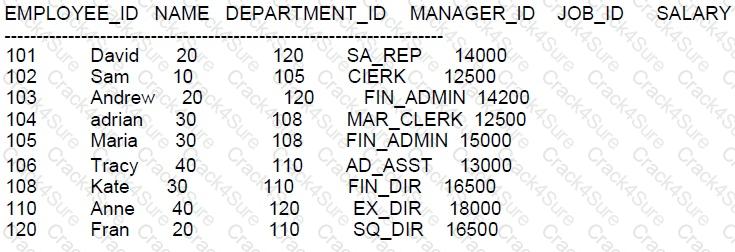
Examine the data in the EMPLOYEES table:
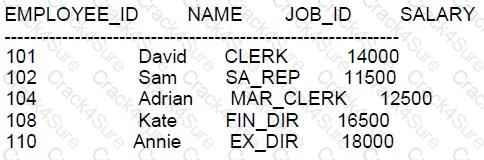
You want to:
1. Update existing employee details in the EMPLOYEES table with data from the NEW EMPLOYEES
table.
2. Add new employee detail from the NEW_ EMPLOYEES able to the EMPLOYEES table.
Which statement will do this:
Examine this data in the EMPLOYERS table?

Which statement will execute successfully?
Examine the description of the EMPLOYEES table:

Examine this query:

Which line produces an error?
Which statement falls to execute successfully?
Examine the description of the CUSTOMERS table:

You want to display details of all customers who reside in cities starting with the letter D followed by at least two character.
Which query can be used?
Which two statements will return the names of the three employees with the lowest salaries?
Which three queries use valid expressions?
Examine this description of the PRODUCTS table:
You successfully execute this command:
CREATE TALE new_prices(prod_id NUBER(2),price NUMBER(8,2));
Which two statements execute without errors?
Examine the description or the BOOKS_TRANSACTIONS table:
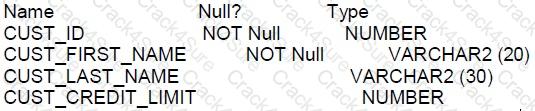
FOR customers whose income level has a value, you want to display the first name and due amount as 5% of their credit limit. Customers whose due amount is null should not be displayed.
Which query should be used?
Examine the description of the EMPLOYEES table:

Which query is valid?
Which three statements are true about performing DML operations on a view with no Instead of triggers defined?
Which two statements are true about the order by clause when used with a sql statement containing a set operator such as union?
Examine the description of the PRODUCTS table:
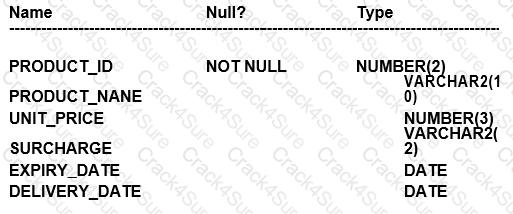
Which three queries use valid expressions?
Examine the description of the PROMOTIONS TABLE:
You want to display the unique is promotion costs in each promotion category.
Which two queries can be used?
Which is the default column or columns for sorting output from compound queries using SET operators such as INTERSECT in a SQL statement?
Which statements are true regarding primary and foreign key constraints and the effect they can have on table data?
Which two tasks require subqueries?
Examine this statement which executes successfully:
Which three are true?
Examine these two queries and their output:
SELECT deptno, dname FROM dept;

SELECT ename, job, deptno FROM emp ORDER BY deptno;

Now examine this query:
SELECT ename, dname
FROM emp CROSS JOIN dept WHERE job = 'MANAGER'
AND dept.deptno IN (10, 20) ;
Examine the description of the CUSTONERS table

CUSTON is the PRIMARY KEY.
You must derermine if any customers’derails have entered more than once using a different
costno,by listing duplicate name
Which two methode can you use to get the requlred resuit?
which is true about the round,truncate and mod functions>?
What is true about non-equijoin statement performance?
Examine the description of the BOOKS_TRANSACTIONS table:

Examine this partial SQL statement:
SELECT * FROM books_transactions
Which two WHERE conditions give the same result?
Which three statements are true about Data Manipulation Language (DML)?
Examine this SQL statement:
SELECT cust_id, cust_last_name "Last Name
FROM customers
WHERE countryid=10
UNION
SELECT custid CUSTNO, cust_last_name
FROM customers
WHERE countryid=30
Identify three ORDER BY clauses, any one of which can complete the query successfully.
Examine the description of the EMPLOYEES table:

Which statement will fail?
Examine this Statement which returns the name of each employee and their manager,
SELECT e.last name AS emp,,m.last_name AS mgr
FROM employees e JOIN managers m
ON e.manager_ id = m. employee_ id ORDER BY emp;
You want to extend the query to include employees with no manager. What must you add before JOIN to do this?
Examine the data in the CUST NAME column of the CUSTOMERS table:
CUST_NAME
------------------------------
Renske Ladwig
Jason Mallin
Samuel McCain
Allan MCEwen
Irene Mikkilineni
Julia Nayer
You want to display the CUST_NAME values where the last name starts with Mc or MC. Which two WHERE clauses give the required result?
The PRODUCT_INFORMATION table has a UNIT_PRICE column of data type NUMBER(8, 2).
Evaluate this SQL statement:
SELECT TO_CHAR(unit_price,'$9,999') FROM PRODUCT_INFORMATION;
Which two statements are true about the output?
Examine the description of the CUSTOMERS table:

Which two SELECT statements will return these results:
CUSTOMER_ NAME
--------------------
Mandy
Mary
The EMPLOYEES table contains columns EMP_ID of data type NUMBER and HIRE_DATE of data type DATE
You want to display the date of the first Monday after the completion of six months since hiring.
The NLS_TERRITORY parameter is set to AMERICA in the session and, therefore, Sunday is the first day of the week Which query can be used?
Which two are SQL features?
Which three statements about roles are true?
You execute this command:
TRUNCATE TABLE dept;
Which two are true?
Examine the description of the BOOKS_TRANSACTIONS table:

Which two WHERE conditions give the same result?
Examine the description of the ENPLYEES table:

Which two queries return all rows for employees whose salary is greater than the average salary in their department?
Which two statements are true about INTERVAL data types
3 Months Free Update
3 Months Free Update
3 Months Free Update

TESTED 10 Jul 2026