We at Crack4sure are committed to giving students who are preparing for the Snowflake ARA-C01 Exam the most current and reliable questions . To help people study, we've made some of our SnowPro Advanced: Architect Certification Exam exam materials available for free to everyone. You can take the Free ARA-C01 Practice Test as many times as you want. The answers to the practice questions are given, and each answer is explained.
What considerations need to be taken when using database cloning as a tool for data lifecycle management in a development environment? (Select TWO).
A company wants to deploy its Snowflake accounts inside its corporate network with no visibility on the internet. The company is using a VPN infrastructure and Virtual Desktop Infrastructure (VDI) for its Snowflake users. The company also wants to re-use the login credentials set up for the VDI to eliminate redundancy when managing logins.
What Snowflake functionality should be used to meet these requirements? (Choose two.)
A large manufacturing company runs a dozen individual Snowflake accounts across its business divisions. The company wants to increase the level of data sharing to support supply chain optimizations and increase its purchasing leverage with multiple vendors.
The company’s Snowflake Architects need to design a solution that would allow the business divisions to decide what to share, while minimizing the level of effort spent on configuration and management. Most of the company divisions use Snowflake accounts in the same cloud deployments with a few exceptions for European-based divisions.
According to Snowflake recommended best practice, how should these requirements be met?
There are two databases in an account, named fin_db and hr_db which contain payroll and employee data, respectively. Accountants and Analysts in the company require different permissions on the objects in these databases to perform their jobs. Accountants need read-write access to fin_db but only require read-only access to hr_db because the database is maintained by human resources personnel.
An Architect needs to create a read-only role for certain employees working in the human resources department.
Which permission sets must be granted to this role?
An Architect runs the following SQL query:

How can this query be interpreted?
A Developer is having a performance issue with a Snowflake query. The query receives up to 10 different values for one parameter and then performs an aggregation over the majority of a fact table. It then
joins against a smaller dimension table. This parameter value is selected by the different query users when they execute it during business hours. Both the fact and dimension tables are loaded with new data in an overnight import process.
On a Small or Medium-sized virtual warehouse, the query performs slowly. Performance is acceptable on a size Large or bigger warehouse. However, there is no budget to increase costs. The Developer
needs a recommendation that does not increase compute costs to run this query.
What should the Architect recommend?
Assuming all Snowflake accounts are using an Enterprise edition or higher, in which development and testing scenarios would be copying of data be required, and zero-copy cloning not be suitable? (Select TWO).
A healthcare company wants to share data with a medical institute. The institute is running a Standard edition of Snowflake; the healthcare company is running a Business Critical edition.
How can this data be shared?
A company is using a Snowflake account in Azure. The account has SAML SSO set up using ADFS as a SCIM identity provider. To validate Private Link connectivity, an Architect performed the following steps:
* Confirmed Private Link URLs are working by logging in with a username/password account
* Verified DNS resolution by running nslookups against Private Link URLs
* Validated connectivity using SnowCD
* Disabled public access using a network policy set to use the company’s IP address range
However, the following error message is received when using SSO to log into the company account:
IP XX.XXX.XX.XX is not allowed to access snowflake. Contact your local security administrator.
What steps should the Architect take to resolve this error and ensure that the account is accessed using only Private Link? (Choose two.)
Data is being imported and stored as JSON in a VARIANT column. Query performance was fine, but most recently, poor query performance has been reported.
What could be causing this?
A company is trying to Ingest 10 TB of CSV data into a Snowflake table using Snowpipe as part of Its migration from a legacy database platform. The records need to be ingested in the MOST performant and cost-effective way.
How can these requirements be met?
A Snowflake Architect is designing a multi-tenant application strategy for an organization in the Snowflake Data Cloud and is considering using an Account Per Tenant strategy.
Which requirements will be addressed with this approach? (Choose two.)
A Snowflake Architect is setting up database replication to support a disaster recovery plan. The primary database has external tables.
How should the database be replicated?
Is it possible for a data provider account with a Snowflake Business Critical edition to share data with an Enterprise edition data consumer account?
Database DB1 has schema S1 which has one table, T1.
DB1 --> S1 --> T1
The retention period of EG1 is set to 10 days.
The retention period of s: is set to 20 days.
The retention period of t: Is set to 30 days.
The user runs the following command:
Drop Database DB1;
What will the Time Travel retention period be for T1?
What integration object should be used to place restrictions on where data may be exported?
Which technique will efficiently ingest and consume semi-structured data for Snowflake data lake workloads?
Two queries are run on the customer_address table:
create or replace TABLE CUSTOMER_ADDRESS ( CA_ADDRESS_SK NUMBER(38,0), CA_ADDRESS_ID VARCHAR(16), CA_STREET_NUMBER VARCHAR(IO) CA_STREET_NAME VARCHAR(60), CA_STREET_TYPE VARCHAR(15), CA_SUITE_NUMBER VARCHAR(10), CA_CITY VARCHAR(60), CA_COUNTY
VARCHAR(30), CA_STATE VARCHAR(2), CA_ZIP VARCHAR(10), CA_COUNTRY VARCHAR(20), CA_GMT_OFFSET NUMBER(5,2), CA_LOCATION_TYPE
VARCHAR(20) );
ALTER TABLE DEMO_DB.DEMO_SCH.CUSTOMER_ADDRESS ADD SEARCH OPTIMIZATION ON SUBSTRING(CA_ADDRESS_ID);
Which queries will benefit from the use of the search optimization service? (Select TWO).
An Architect is troubleshooting a query with poor performance using the QUERY function. The Architect observes that the COMPILATION_TIME Is greater than the EXECUTION_TIME.
What is the reason for this?
An Architect is using an event table associated with a Sales database (sales_db) to track logging and tracing of procedures and functions. The event table is also used to refresh dynamic tables.
A stored procedure causing issues resides in the Marketing database (marketing_db). Both databases are in the same Snowflake account. The Marketing database is not associated with a specific event table.
How can the Architect investigate the issue?
What is a characteristic of loading data into Snowflake using the Snowflake Connector for Kafka?
A company needs to have the following features available in its Snowflake account:
1. Support for Multi-Factor Authentication (MFA)
2. A minimum of 2 months of Time Travel availability
3. Database replication in between different regions
4. Native support for JDBC and ODBC
5. Customer-managed encryption keys using Tri-Secret Secure
6. Support for Payment Card Industry Data Security Standards (PCI DSS)
In order to provide all the listed services, what is the MINIMUM Snowflake edition that should be selected during account creation?
A retail company has over 3000 stores all using the same Point of Sale (POS) system. The company wants to deliver near real-time sales results to category managers. The stores operate in a variety of time zones and exhibit a dynamic range of transactions each minute, with some stores having higher sales volumes than others.
Sales results are provided in a uniform fashion using data engineered fields that will be calculated in a complex data pipeline. Calculations include exceptions, aggregations, and scoring using external functions interfaced to scoring algorithms. The source data for aggregations has over 100M rows.
Every minute, the POS sends all sales transactions files to a cloud storage location with a naming convention that includes store numbers and timestamps to identify the set of transactions contained in the files. The files are typically less than 10MB in size.
How can the near real-time results be provided to the category managers? (Select TWO).
A Snowflake Architect is designing an application and tenancy strategy for an organization where strong legal isolation rules as well as multi-tenancy are requirements.
Which approach will meet these requirements if Role-Based Access Policies (RBAC) is a viable option for isolating tenants?
A company is storing large numbers of small JSON files (ranging from 1-4 bytes) that are received from IoT devices and sent to a cloud provider. In any given hour, 100,000 files are added to the cloud provider.
What is the MOST cost-effective way to bring this data into a Snowflake table?
An Architect Is designing a data lake with Snowflake. The company has structured, semi-structured, and unstructured data. The company wants to save the data inside the data lake within the Snowflake system. The company is planning on sharing data among Its corporate branches using Snowflake data sharing.
What should be considered when sharing the unstructured data within Snowflake?
When using the copy into <table> command with the CSV file format, how does the match_by_column_name parameter behave?
A Snowflake Architect created a new data share and would like to verify that only specific records in secure views are visible within the data share by the consumers.
What is the recommended way to validate data accessibility by the consumers?
What are purposes for creating a storage integration? (Choose three.)
What is a valid object hierarchy when building a Snowflake environment?
Which query will identify the specific days and virtual warehouses that would benefit from a multi-cluster warehouse to improve the performance of a particular workload?
A)
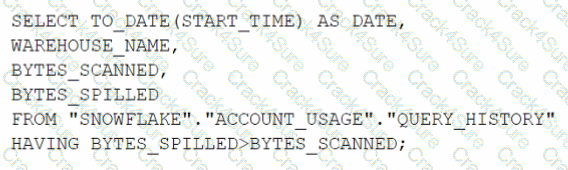
B)
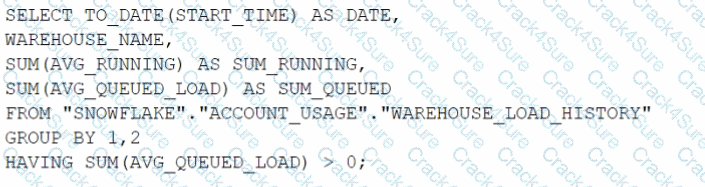
C)
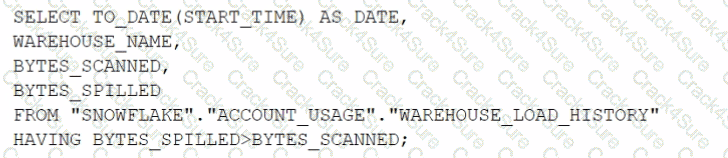
D)

You are a snowflake architect in an organization. The business team came to to deploy an use case which requires you to load some data which they can visualize through tableau. Everyday new data comes in and the old data is no longer required.
What type of table you will use in this case to optimize cost
A media company needs a data pipeline that will ingest customer review data into a Snowflake table, and apply some transformations. The company also needs to use Amazon Comprehend to do sentiment analysis and make the de-identified final data set available publicly for advertising companies who use different cloud providers in different regions.
The data pipeline needs to run continuously ang efficiently as new records arrive in the object storage leveraging event notifications. Also, the operational complexity, maintenance of the infrastructure, including platform upgrades and security, and the development effort should be minimal.
Which design will meet these requirements?
User1 and User2 are new users that were granted different functional roles.
User1 was granted the IT_ANALYST_ROLE
User2 was granted the FIN_ANALYST_ROLE
Review the following security design (as shown in the diagram):

A database (DB) grants USAGE and SELECT on all tables to DB_IT_RO_ROLE
DB_IT_RO_ROLE is granted to IT_ANALYST_ROLE
IT_SCHEMA contains TABLE1
FINANCE_SCHEMA grants USAGE and SELECT to DB_FIN_ROLE
DB_FIN_ROLE is granted to FIN_ANALYST_ROLE
FINANCE_SCHEMA contains FIN_TABLE
Which tables can each user read?
A company is following the Data Mesh principles, including domain separation, and chose one Snowflake account for its data platform.
An Architect created two data domains to produce two data products. The Architect needs a third data domain that will use both of the data products to create an aggregate data product. The read access to the data products will be granted through a separate role.
Based on the Data Mesh principles, how should the third domain be configured to create the aggregate product if it has been granted the two read roles?
An Architect needs to automate the daily Import of two files from an external stage into Snowflake. One file has Parquet-formatted data, the other has CSV-formatted data.
How should the data be joined and aggregated to produce a final result set?
A company has several sites in different regions from which the company wants to ingest data.
Which of the following will enable this type of data ingestion?
Role A has the following permissions:
. USAGE on db1
. USAGE and CREATE VIEW on schemal in db1
. SELECT on tablel in schemal
Role B has the following permissions:
. USAGE on db2
. USAGE and CREATE VIEW on schema2 in db2
. SELECT on table2 in schema2
A user has Role A set as the primary role and Role B as a secondary role.
What command will fail for this user?
A company has a Snowflake environment running in AWS us-west-2 (Oregon). The company needs to share data privately with a customer who is running their Snowflake environment in Azure East US 2 (Virginia).
What is the recommended sequence of operations that must be followed to meet this requirement?
Which steps are recommended best practices for prioritizing cluster keys in Snowflake? (Choose two.)
An Architect has selected the Snowflake Connector for Python to integrate and manipulate Snowflake data using Python to handle large data sets and complex analyses.
Which features should the Architect consider in terms of query execution and data type conversion? (Select TWO).
A retailer's enterprise data organization is exploring the use of Data Vault 2.0 to model its data lake solution. A Snowflake Architect has been asked to provide recommendations for using Data Vault 2.0 on Snowflake.
What should the Architect tell the data organization? (Select TWO).
An Architect executes the following statements in order:
CREATE TABLE emp (id INTEGER);
INSERT INTO emp VALUES (1),(2);
CREATE TEMPORARY TABLE emp (id INTEGER);
INSERT INTO emp VALUES (1);
Then executes:
SELECT COUNT(*) FROM emp;
DROP TABLE emp;
SELECT COUNT(*) FROM emp;
What will be the result?
Which Snowflake data modeling approach is designed for BI queries?
An Architect with the ORGADMIN role wants to change a Snowflake account from an Enterprise edition to a Business Critical edition.
How should this be accomplished?
A user, analyst_user has been granted the analyst_role, and is deploying a SnowSQL script to run as a background service to extract data from Snowflake.
What steps should be taken to allow the IP addresses to be accessed? (Select TWO).
An Architect wants to stream website logs near real time to Snowflake using the Snowflake Connector for Kafka.
What characteristics should the Architect consider regarding the different ingestion methods? (Select TWO).
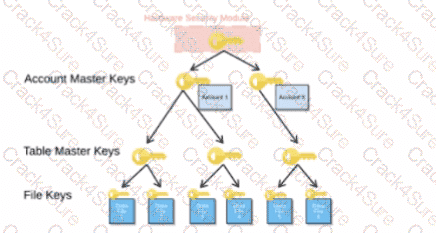
When activating Tri-Secret Secure in a hierarchical encryption model in a Snowflake account, at what level is the customer-managed key used?
Which SQL alter command will MAXIMIZE memory and compute resources for a Snowpark stored procedure when executed on the snowpark_opt_wh warehouse?
A)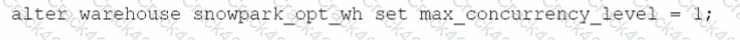
B)
C)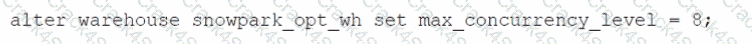
D)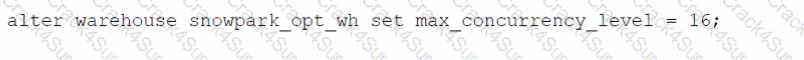
3 Months Free Update
3 Months Free Update
3 Months Free Update

TESTED 31 Jul 2026