We at Crack4sure are committed to giving students who are preparing for the UiPath UiPath-SAIv1 Exam the most current and reliable questions . To help people study, we've made some of our UiPath Certified Professional Specialized AI Professional v1.0 exam materials available for free to everyone. You can take the Free UiPath-SAIv1 Practice Test as many times as you want. The answers to the practice questions are given, and each answer is explained.
How do partially labeled messages impact label predictions in UiPath Communications Mining?
How does UiPath Document Understanding handle structured documents with fixed formats?
What are all the types of ML (Machine Learning) models supported by Al Center?
For what type of documents is it recommended to use the RegEx Based Extractor?
How can the code be tested in a development or testing environment in the context of the Document Understanding Process?
How long does the typical Machine Learning model deployment process take in UiPath AI Center?
What happens to your document and the process of pre-labeling when you choose the "Predict" option from the "Predict" dropdown in Document Manager?
What is the primary function of the Wait for Classification Validation Task and Resume activity In UiPath's Document Understanding Framework?
What are the out-of-the-box packages types available in Al Center?
What additional information can be included in the exported data, apart from the extraction results?
What is the definition of a UiPath Communications Mining data source?
When a parent label is deleted in UiPath Communications Mining, what happens to the training data tor that label?
What is the purpose of UiPath Communications Mining?
What is the benefit of making an ML Skill public?
On at least how many different pages should a regular field be labeled in Data Manager before Exporting the labeled documents to Al Center?
Which of the following is a best practice when choosing a UiPath ML (Machine Learning) Extractor?
Which activity can be used to convert the default taxonomy.json file into a variable for further use?
What is the correct execution order of the Document Understanding template stages?
Instructions: Drag the stages found on the "Left" and drop them on the "Right” in the correct order.

Can you use Queues in the Document Understanding Process?
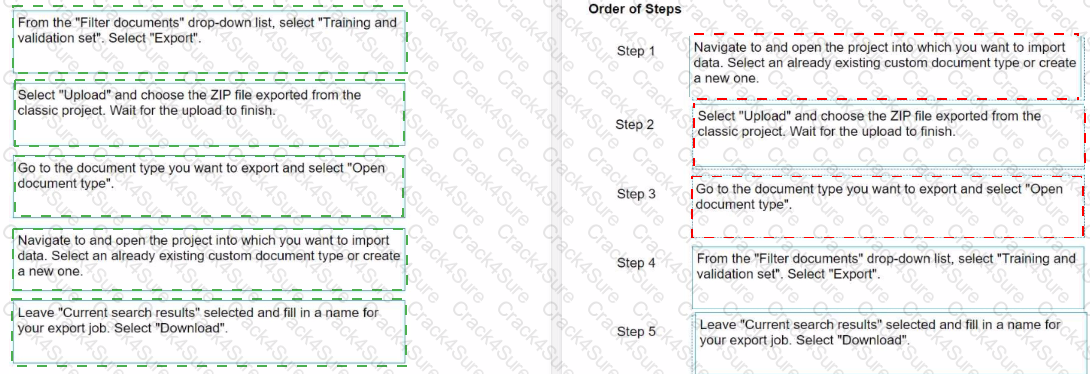
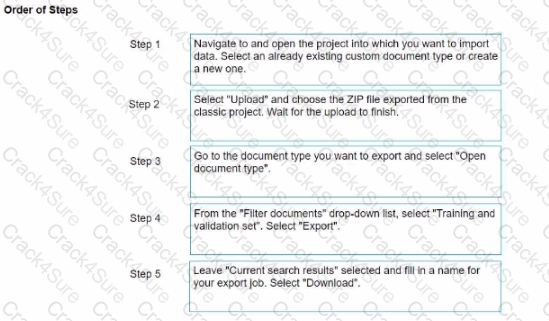
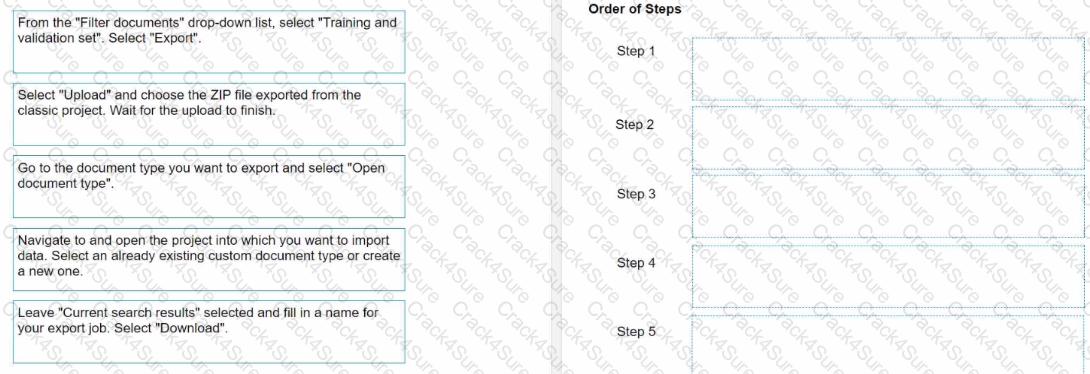
What is the correct order of migrating a dataset from Document Manager to a Modern Project? Instructions: Drag the Description found on the left and drop on the correct Step found on the right.
What is the role of the dispatcher in the Document Understanding Process?
Which UiPath Communications Mining model performance factor assesses the proportion of the entire dataset that has informative label predictions?
How many types of synchronization mechanisms exist in the Document Understanding Process to prevent multiple robots to write in a file at the same time?2
What information should be provided when adding a classification label for the OOB (Out Of the Box) labeling template?
Which statement accurately describes out-of-the-box models in UiPath?
Which of the following extractors can be used for Data Extraction Scope activity?
Which validation checks are performed for ML packages uploaded with the Enable Training option inactive?
What can the Sentiment Analysis out-of-the-box model be used for?
What is the primary metric used to calculate the score for the All Labels performance factor in UiPath Communications Mining?
Which are the the minimum required inputs in order to configure the Classification Station as an attended activity?
What does a UiPath Communications Mining taxonomy include?
Which of these statements is true about precision and recall statistics for specific labels in UiPath Communications Mining precision?
What will be the behavior of the process if, during design time, the property ValidateUnconnectedNodes is set to True on a flowchart and a Log Message activity from this flowchart is not connected to any other node?
What information does the comparison between two cohorts display on the Comparison page in UiPath Communications Mining?
Which is a high-level view of the tabs within an AI Center project?
A developer has created a string array variable as shown below:
UserNames = {"Jane", "Jack", "Jill", "John"}
Which expression should the developer use in a Log Message activity to print the elements of the array separated by the string ","?
Which of the following functionalities does UiPath Assistant provide?
Which scenario would be best accomplished using unattended automation?
What is the difference between OCR (Optical Character Recognition) and IntelligentOCR?
When designing the Taxonomy for document types, what should be a primary consideration?
Which of the below is the correct definition of "recall" in UiPath Communications Mining?
What is the role of the Taxonomy Manager?
How are UiPath RPA and AI Center used for process improvement?
What is a reason for pinning a UiPath Communications Mining Model?
What is the default visibility of an ML skill?
In UiPath Communications Mining, what does the Reports section contain?
Which features in Generative Annotation are automatically enabled on datasets in Communication Mining technology?
How do the prediction mechanisms for labels and general fields differ in the UiPath Communications Mining platform?
Which of the following best describes UiPath Document Understanding?
What rule should be used in Taxonomy Manager for a text field that can have one of multiple known values?
What do entities represent in UiPath Communications Mining?
Under what condition can a dataset be deleted in UiPath Al Center?
For what type of documents is it recommended to use the Form Extractor?
Under what condition can a project be deleted in UiPath AI Center?
Which role is responsible for building and uploading ML (Machine Learning) models lo Al Center?
How can a Pipeline be scheduled?
Which of the following options contains the correct list of Default actions that can be found in Workflow Analyzer Settings?
How do you choose the appropriate document processing methodology?
3 Months Free Update
3 Months Free Update
3 Months Free Update

TESTED 09 Jul 2026