We at Crack4sure are committed to giving students who are preparing for the Databricks Databricks-Machine-Learning-Professional Exam the most current and reliable questions . To help people study, we've made some of our Databricks Certified Machine Learning Professional exam materials available for free to everyone. You can take the Free Databricks-Machine-Learning-Professional Practice Test as many times as you want. The answers to the practice questions are given, and each answer is explained.
A machine learning engineer is attempting to create a webhook that will trigger a Databricks Jobjob_idwhen a model version for modelmodeltransitions into any MLflow Model Registry stage.
They have the following incomplete code block:

Which of the following lines of code can be used to fill in the blank so that the code block accomplishes the task?
Which of the following describes the purpose of the context parameter in the predict method of Python models for MLflow?
Which of the following describes the concept of MLflow Model flavors?
A data scientist has developed and logged a scikit-learn random forest model model, and then they ended their Spark session and terminated their cluster. After starting a new cluster, they want to review the feature_importances_ of the original model object.
Which of the following lines of code can be used to restore the model object so that feature_importances_ is available?
A machine learning engineer and data scientist are working together to convert a batch deployment to an always-on streaming deployment. The machine learning engineer has expressed that rigorous data tests must be put in place as a part of their conversion to account for potential changes in data formats.
Which of the following describes why these types of data type tests and checks are particularly important for streaming deployments?
Which of the following describes label drift?
Which of the following machine learning model deployment paradigms is the most common for machine learning projects?
A machine learning engineer wants to deploy a model for real-time serving using MLflow Model Serving. For the model, the machine learning engineer currently has one model version in each of the stages in the MLflow Model Registry. The engineer wants to know which model versions can be queried once Model Serving is enabled for the model.
Which of the following lists all of the MLflow Model Registry stages whose model versions are automatically deployed with Model Serving?
Which of the following is a simple, low-cost method of monitoring numeric feature drift?
A machine learning engineer is converting a Hyperopt-based hyperparameter tuning process from manual MLflow logging to MLflow Autologging. They are trying to determine how to manage nested Hyperopt runs with MLflow Autologging.
Which of the following approaches will create a single parent run for the process and a child run for each unique combination of hyperparameter values when using Hyperopt and MLflow Autologging?
A data scientist is using MLflow to track their machine learning experiment. As a part of each MLflow run, they are performing hyperparameter tuning. The data scientist would like to have one parent run for the tuning process with a child run for each unique combination of hyperparameter values.
They are using the following code block:

The code block is not nesting the runs in MLflow as they expected.
Which of the following changes does the data scientist need to make to the above code block so that it successfully nests the child runs under the parent run in MLflow?
Which of the following MLflow operations can be used to delete a model from the MLflow Model Registry?
A machine learning engineer has created a webhook with the following code block:

Which of the following code blocks will trigger this webhook to run the associate job?
A)
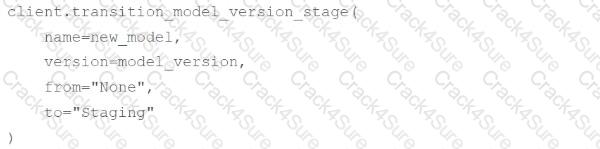
B)

C)

D)

E)

3 Months Free Update
3 Months Free Update
3 Months Free Update

TESTED 24 Feb 2026
